Folders
Files
{kind=link}
DESCRIPTION
index.html
next_motif.gif
{kind=link}
PACKAGES
previous_motif.gif
{kind=link}
R-logo.gif
{kind=link}
Simple_0.6.tar.gz
Simple_0.6.zip
simpleR.R
stat.html
stat001.gif
{kind=link}
stat001.html
stat002.gif
{kind=link}
stat002.html
stat003.gif
{kind=link}
stat003.html
stat004.gif
{kind=link}
stat004.html
stat005.gif
{kind=link}
stat005.html
stat006.gif
{kind=link}
stat006.html
stat007.gif
{kind=link}
stat007.html
stat008.gif
{kind=link}
stat008.html
stat009.gif
{kind=link}
stat009.html
stat010.gif
{kind=link}
stat010.html
stat011.gif
{kind=link}
stat011.html
stat012.gif
{kind=link}
stat012.html
stat013.gif
{kind=link}
stat013.html
stat014.gif
{kind=link}
stat014.html
stat015.gif
{kind=link}
stat015.html
stat016.gif
{kind=link}
stat016.html
stat017.gif
{kind=link}
stat017.html
stat018.gif
{kind=link}
stat018.html
stat019.gif
{kind=link}
stat019.html
stat020.gif
{kind=link}
stat020.html
stat021.gif
{kind=link}
stat021.html
stat022.gif
{kind=link}
stat022.html
stat023.gif
{kind=link}
stat023.html
stat024.gif
{kind=link}
stat024.html
stat025.gif
{kind=link}
stat025.html
stat026.gif
{kind=link}
stat026.html
stat027.gif
{kind=link}
stat028.gif
{kind=link}
stat029.gif
{kind=link}
stat030.gif
{kind=link}
stat031.gif
{kind=link}
stat032.gif
{kind=link}
stat033.gif
{kind=link}
stat034.gif
{kind=link}
stat035.gif
{kind=link}
stat036.gif
{kind=link}
stat037.gif
{kind=link}
stat038.gif
{kind=link}
stat039.gif
{kind=link}
stat040.gif
{kind=link}
stat041.gif
{kind=link}
stat042.gif
{kind=link}
stat043.gif
{kind=link}
stat044.gif
{kind=link}
stat045.gif
{kind=link}
stat046.gif
{kind=link}
stat047.gif
{kind=link}
stat048.gif
{kind=link}
stat049.gif
{kind=link}
stat050.gif
{kind=link}
stat051.gif
{kind=link}
stat052.gif
{kind=link}
stat053.gif
{kind=link}
stat054.gif
{kind=link}
stat055.gif
{kind=link}
stat056.gif
{kind=link}
stat057.gif
{kind=link}
stat058.gif
{kind=link}
stat059.gif
{kind=link}



10 Hypothesis Testing
Hypothesis testing is mathematically related to the problem of finding confidence intervals. However, the approach is different. For one, you use the data to tell you where the unknown parameters should lie, for hypothesis testing, you make a hypothesis about the value of the unknown parameter and then calculate how likely it is that you observed the data or worse.However, with R you will not notice much difference as the same functions are used for both. The way you use them is slightly different though.
10.1 Testing a population parameter
Consider a simple survey. You ask 100 people (randomly chosen) and 42 say ``yes'' to your question. Does this support the hypothesis that the true proportion is 50%?To answer this, we set up a test of hypothesis. The null hypothesis, denoted H0 is that p=.5, the alternative hypothesis, denoted HA, in this example would be p ą 0.5. This is a so called ``two-sided'' alternative. To test the assumptions, we use the function prop.test as with the confidence interval calculation. Here are the commands
> prop.test(42,100,p=.5)
1-sample proportions test with continuity correction
data: 42 out of 100, null probability 0.5
X-squared = 2.25, df = 1, p-value = 0.1336
alternative hypothesis: true p is not equal to 0.5
95 percent confidence interval:
0.3233236 0.5228954
sample estimates:
p
0.42
Note the p-value of 0.1336. The p-value reports how likely we
are to see this data or worse assuming the null hypothesis.
The notion of worse, is implied by the alternative hypothesis. In
this example, the alternative is two-sided as too small a value or
too large a value or the test statistic is consistent with HA. In
particular, the p-value is the probability of 42 or fewer
or 58 or more answer ``yes'' when the chance a person will
answer ``yes'' is fifty-fifty.Now, the p-value is not so small as to make an observation of 42 seem unreasonable in 100 samples assuming the null hypothesis. Thus, one would ``accept'' the null hypothesis.
Next, we repeat, only suppose we ask 1000 people and 420 say yes. Does this still support the null hypothesis that p=0.5?
> prop.test(420,1000,p=.5)
1-sample proportions test with continuity correction
data: 420 out of 1000, null probability 0.5
X-squared = 25.281, df = 1, p-value = 4.956e-07
alternative hypothesis: true p is not equal to 0.5
95 percent confidence interval:
0.3892796 0.4513427
sample estimates:
p
0.42
Now the p-value is tiny (that's 0.0000004956!) and the null
hypothesis is not supported. That is, we ``reject'' the null
hypothesis. This illustrates the the p value depends not just on the
ratio, but also n. In particular, it is because the standard error
of the sample average
gets smaller as n gets larger.
10.2 Testing a mean
Suppose a car manufacturer claims a model gets 25 mpg. A consumer group asks 10 owners of this model to calculate their mpg and the mean value was 22 with a standard deviation of 1.5. Is the manufacturer's claim supported? 12In this case H0: µ = 25 against the one-sided alternative hypothesis that µ<25. To test using R we simply need to tell R about the type of test. (As well, we need to convince ourselves that the t-test is appropriate for the underlying parent population.) For this example, the built-in R function t.test isn't going to work -- the data is already summarized -- so we are on our own. We need to calculate the test statistic and then find the p-value.
## Compute the t statistic. Note we assume mu=25 under H_0 > xbar=22;s=1.5;n=10 > t = (xbar-25)/(s/sqrt(n)) > t [1] -6.324555 ## use pt to get the distribution function of t > pt(t,df=n-1) [1] 6.846828e-05This is a small p-value (0.000068). The manufacturer's claim is suspicious.
10.3 Tests for the median
Suppose a study of cell-phone usage for a user gives the following lengths for the calls
12.8 3.5 2.9 9.4 8.7 .7 .2
2.8 1.9 2.8 3.1 15.8
What is an appropriate test for center?First, look at a stem and leaf plot
x = c(12.8,3.5,2.9,9.4,8.7,.7,.2,2.8,1.9,2.8,3.1,15.8) > stem(x) ... 0 | 01233334 0 | 99 1 | 3 1 | 6The distribution looks skewed with a possibly heavy tail. A t-test is ruled out. Instead, a test for the median is done. Suppose H0 is that the median is 5, and the alternative is the median is bigger than 5. To test this with R we can use the wilcox.test as follows
> wilcox.test(x,mu=5,alt="greater")
Wilcoxon signed rank test with continuity correction
data: x
V = 39, p-value = 0.5156
alternative hypothesis: true mu is greater than 5
Warning message:
Cannot compute exact p-value with ties ...
Note the p value is not small, so the null hypothesis is not rejected.
Some Extra Insight: Rank tests
The test wilcox.test is a signed rank test. Many books first introduce the sign test, where ranks are not considered. This can be calculated using R as well. A function to do so is simple.median.test. This computes the p-value for a two-sided test for a specified median.
To see it work, we have
The test wilcox.test is a signed rank test. Many books first introduce the sign test, where ranks are not considered. This can be calculated using R as well. A function to do so is simple.median.test. This computes the p-value for a two-sided test for a specified median.
To see it work, we have
> x = c(12.8,3.5,2.9,9.4,8.7,.7,.2,2.8,1.9,2.8,3.1,15.8) > simple.median.test(x,median=5) [1] 0.3876953 # accept > simple.median.test(x,median=10) [1] 0.03857422 # reject
10.4 Problems
- 10.1
- Load the Simple data set vacation. This gives
the number of paid holidays and vacation taken by workers in the
textile industry.
- Is a test for y-- appropriate for this data?
- Does a t-test seem appropriate?
- If so, test the null hypothesis that µ = 24. (What is the alternative?)
- 10.2
- Repeat the above for the Simple data set smokyph. This data set measures pH levels for water samples in the Great Smoky Mountains. Use the waterph column (smokyph[['waterph']]) to test the null hypothesis that µ=7. What is a reasonable alternative?
- 10.3
- An exit poll by a news station of 900 people in the state of Florida found 440 voting for Bush and 460 voting for Gore. Does the data support the hypothesis that Bush received p=50% of the state's vote?
- 10.4
- Load the Simple data set cancer. Look only at
cancer[['stomach']]. These are survival times for stomach
cancer patients taking a large dosage of Vitamin C. Test the null
hypothesis that the Median is 100 days. Should you also use a
t-test? Why or why not?
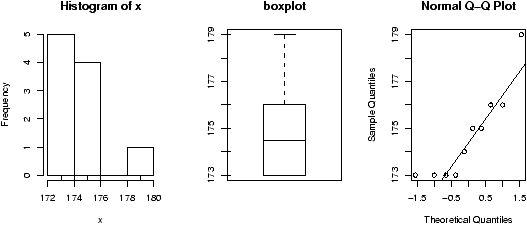
(A boxplot of the cancer data is interesting.)
Copyright © John Verzani, 2001-2. All rights reserved.