Optimizers¶
Keras includes support for a range of optimization algorithms:
SGD- Stochastic Gradient DescentRMSprop- normalizes the gradient by a running average of recent magnitudesAdagrad- Adaptive gradient descent: updates shrink for parameters that are updated oftenAdadelta- More robust AdagradAdam- Adaptive Momentum EstimationAdamax- Version of Adam that uses the infinity normNadam- Adam with Nesterov momentum
Stochastic Gradient Descent¶
Pretty much all our methods build on some version of Stochastic Gradient Descent:
- Select samples at random
- Numerically compute the gradients at these samples
- Average the gradients
- Take a small step in the direction of the average gradient
Two main adjustments are made in different methods:
- Momentum: include previous gradients in calculating the current update
- Adaptation: adjust step sizes based on how often a feature is updated.
Adaptive Gradient Descent¶
RMSprop¶
Root Mean Square Propagation adjusts the learning rate separately for each parameter by dividing it by a running average of the magnitudes of recent gradients.
Adagrad¶
Increases learning rates for rarely occurring parameters, and decreases for more common parameters.
AdaDelta¶
More robust variation on Adagrad
Momentum¶
Learning with momentum includes the previous updates as a term in calculating the next update.
It tends to prevent oscillation around an optimum.
Nesterov Momentum¶
One comment version is Nesterov Momentum: first extrapolate with preceding update. Then move according to the extrapolated position

(blue: momentum; brown: Nesterov extrapolation; red: Nesterov correction)
Adam¶
Adam tracks an exponentially decaying average of past gradients as a more adaptive momentum. Basically, this is RMSprop combined with a momentum term.
AdaMax changes the $L_2$ norm used in Adam into an $L_\infty$ norm.
Nadam uses Nesterov momentum.
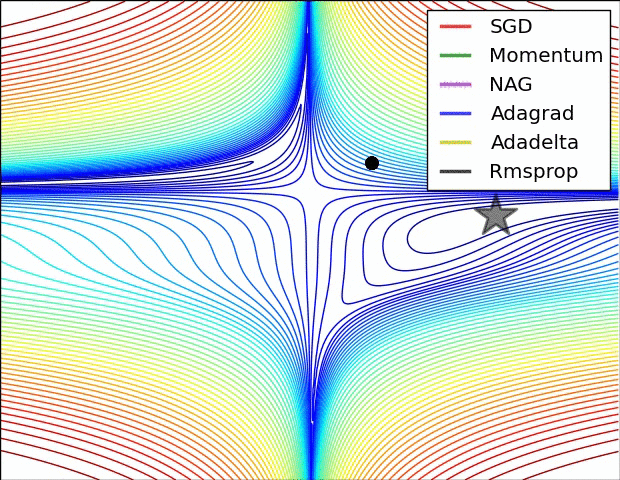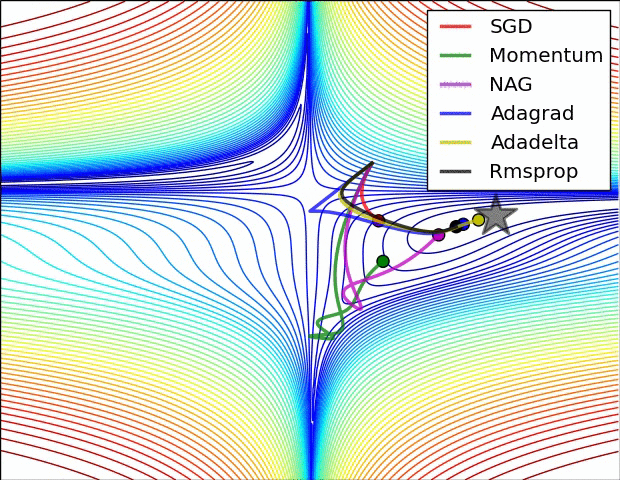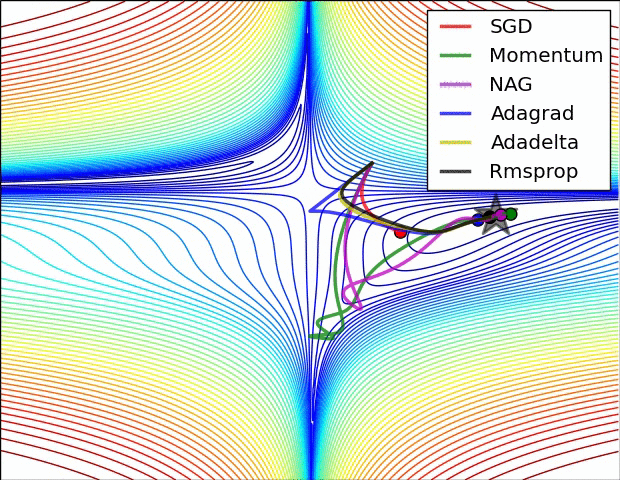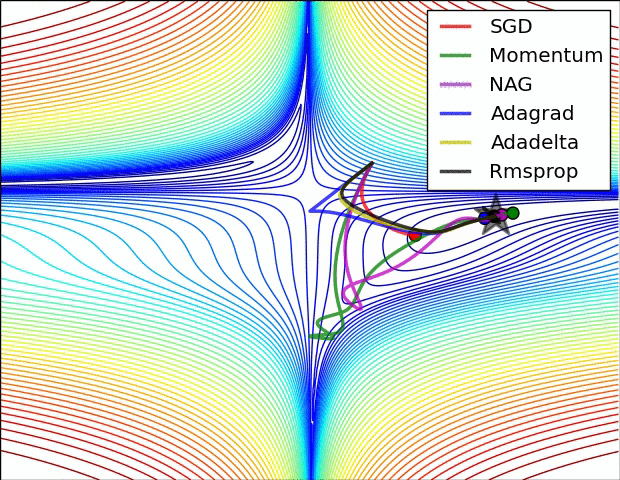
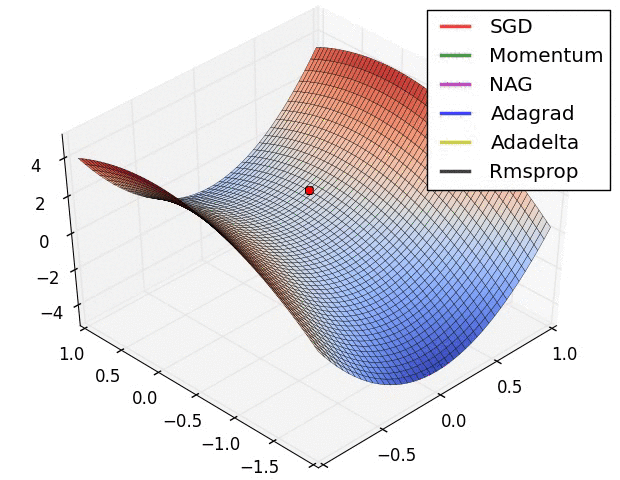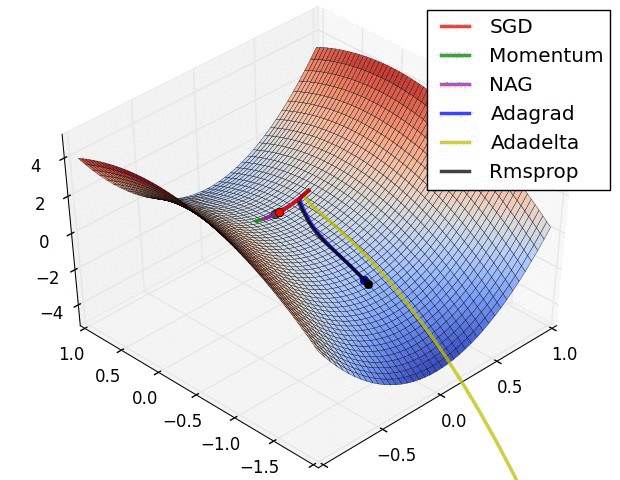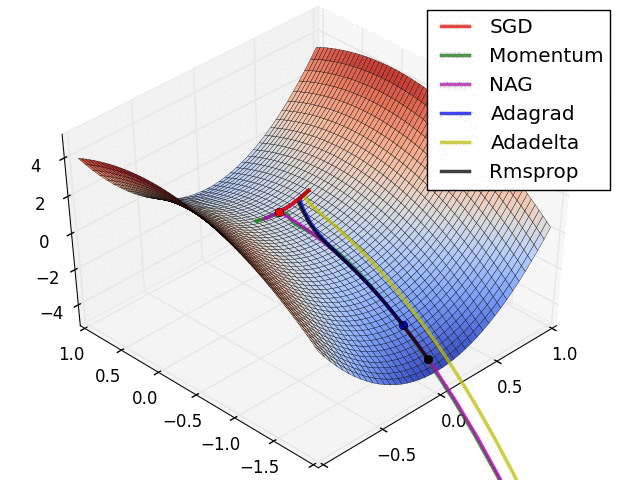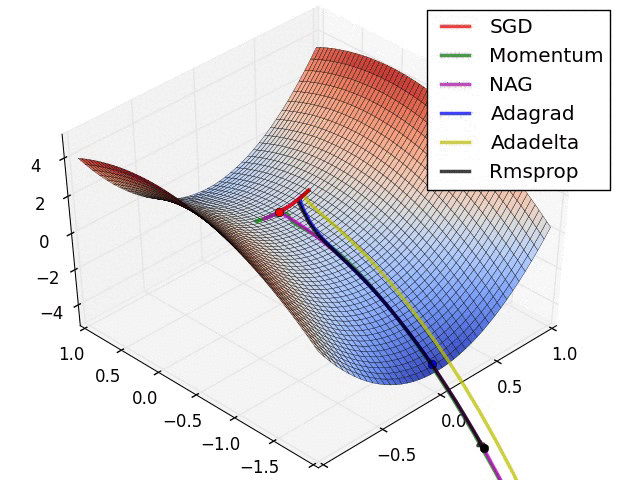
So which do I pick?¶
- Sparse data? use adaptive learning methods. RMSprop, Adagrad, Adadelta, Adam all are similar. Some papers suggest Adam slightly outperforms RMSprop towards the end.
- Shallow network? SGD with Nesterov momentum works well for relatively simple cases.
So I read this paper, and...¶
A lot of deep learning papers build their network architectures by creating smaller modules and combining these. Keras can do similar constructions by treating Keras models as network layers, or by using the Functional API. One way is to subclass the Keras layer class and override the call method. Here is another way, implementing residual networks with skipping layers:
from tensorflow.keras import layers
def res_cell(inputs, layers, n_channels, strides=1):
inputs_copy = layers.Activation("linear", trainable=False)(inputs)
x = layers.Conv2D(n_channels, (3,3), strides, padding="same", activation="relu")(inputs)
for _ in range(layers-2):
x = layers.Conv2D(n_channels, (3,3), padding="same", activation="relu")(x)
x = layers.Conv2D(n_channels, (3,3), padding="same")(x)
residual = layers.Add()([inputs_copy, x])
x = layers.Activation("relu")(residual)
return x
inputs = layers.Input(shape=(192,192,3))
x = layers.Conv2D(64, (7,7), 2)(inputs)
x = layers.MaxPooling2D()(x)
x = res_cell(x, 2, 64)
x = res_cell(x, 2, 64)
x = res_cell(x, 2, 64)
x = res_cell(x, 2, 128, strides=2)
x = res_cell(x, 2, 128)
x = res_cell(x, 2, 128)
x = res_cell(x, 2, 128)
x = res_cell(x, 2, 256, strides=2)
x = res_cell(x, 2, 256)
x = res_cell(x, 2, 256)
x = res_cell(x, 2, 256)
x = res_cell(x, 2, 256)
x = res_cell(x, 2, 256)
x = res_cell(x, 2, 512, strides=2)
x = res_cell(x, 2, 512)
x = res_cell(x, 2, 512)
x = layers.AveragePooling2D()(x)
outputs = layers.Dense(1000, activation="softmax")(x)