What about overfitting?¶
Convolutional networks can be prone to overfitting - especially on small datasets. There are several strategies to deal with this problem:
- Regularization
- Training Data Augmentation
- Pooling Layers
- Dropout Layers
fig1

Regularization¶
Just like with regressions, regularization can help. Add a term to the error that measures size of the coefficients - $L_1$ or $L_2$ or some other choice - to suppress overfitting.
In Keras: layers take the options
kernel_regularizer=...: Regularizer function applied to the kernel weights matrix.bias_regularizer=...: Regularizer function applied to the bias vector.activity_regularizer=...: Regularizer function applied to the output of the layer (its "activation").
These take either objects from keras.regularizer or strings "l1" or "l2" or "l1_l2"
fig2

Training Data Augmentation¶
Reading digits is a task that can be tightly controlled: preprocessing can locate, isolate and center the digit itself. For more natural vision tasks it can be difficult to get sufficiently much variety when it comes to lighting, position in the frame, angle of picture etc.
One way to compensate is to generate new training (or validation or testing) samples by modifying the existing training/validation/testing data.
Image Data Augmentation in Keras¶
Keras used to have a preprocessing submodule. That functionality has been deprecated in favor of using TensorFlow's Dataset setup.
TensorFlow Dataset objects can be created in a few ways:
tf.data.Dataset.from_tensors()ortf.data.Dataset.from_tensor_slices()- data is in TensorFlow tensors, numpy arrays or Python lists.tf.data.experimental.make_csv_dataset()- data is in CSV files.tf.data.TextLineDataset- each data point is a line in a text file (ex. text corpuses, CSV-files)tf.data.FixedLengthRecordDataset- each data point is a fixed length binary file recordtf.data.TFRecordDataset- the data is saved in the TFRecord data file format
Image Data Augmentation in Keras¶
In the boilerplate code we could find a function for encapsulating reading and preparing the training data:
def data_augment(image, label):
# fill here with data augmentation manipulations later
return image, label
def get_training_dataset():
dataset = load_dataset(TRAINING_FILENAMES, labeled=True)
dataset = dataset.map(data_augment, num_parallel_calls=AUTOTUNE)
dataset = dataset.repeat()
dataset = dataset.shuffle(2048)
dataset = dataset.batch(BATCH_SIZE)
dataset = dataset.prefetch(AUTOTUNE)
return dataset
The function data_augment here is a placeholder, to be filled with function calls to modify and prepare images before feeding them into the rest of the pipeline.
Image Data Augmentation in Keras¶
The submodule tf.image has a wide selection of image processing functions - both for reading image formats, for converting color space, and for applying randomly chosen image augmentation operations. These include:
tf.image.stateless_random_flip_left_right- randomly reflect the image horizontallytf.image.stateless_random_flip_up_down- randomly reflect the image verticallytf.image.stateless_random_crop- randomly crop to a sub-imagetf.image.stateless_random_jpeg_quality- randomly degrade image compression qualitytf.image.stateless_random_hue- randomly rotate all hues in the imagetf.image.stateless_random_saturation- randomly change the saturation of an imagetf.image.stateless_random_brightness- randomly change the brightness of the imagetf.image.stateless_random_contrast- randomly change the contrast of the image
Image Data Augmentation in Keras¶
You can also use Keras preprocessing layers to build the augmentation into the model instead of into the data loading stream. These layers are only active during training, and simply pass data through when using the model:
tf.keras.layers.RandomCroptf.keras.layers.RandomFliptf.keras.layers.RandomTranslationtf.keras.layers.RandomRotationtf.keras.layers.RandomZoomtf.keras.layers.RandomHeighttf.keras.layers.RandomWidthtf.keras.layers.RandomContrast
Tradeoffs with Image Data Augmentation in Keras¶
These two approaches - tf.image or the Keras preprocessing layers - result in different handling of the data.
tf.imagewill preprocess only on CPU, not drawing any GPU/TPU acceleration. But it will happen asynchronously and efficiently in parallel with training. This is recommended forTextVectorization, for structured preprocessing layers, and if you are working without accelerators.- Keras preprocessing layers will process on GPU/TPU and will benefit from acceleration. It is recommended for the
Normalizationlayer and all image preprocessing and data augmentation layers.
Image Augmentation¶
fig3

Pooling Layers¶
Another way to control complexity and reduce overfitting is to simply down-sample the filters regularly. This is the role of a pooling layer. Most commonly used is max pooling:
- Choose kernel and stride
- Slide the kernel around the width/height dimensions and reduce each window to its maximum
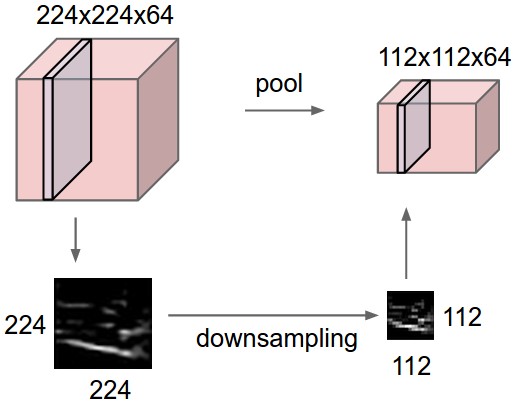
(image from Karpathy's lecture notes)
Max Pooling¶
One issue with the MNIST data sets and demonstrating max pooling is that the images are so small that down-sampling them removes a lot of structure.
fig4

Max Pooling in Keras¶
keras.layers.MaxPooling2D takes as its first argument the size of the pooling window. Second, optional, is the stride to use.
Keras also has MaxPooling1D and MaxPooling3D, as well as average pooling layers for all three sizes.
Dropout Layers¶
Dropout layers randomly set some subset of activations to 0.
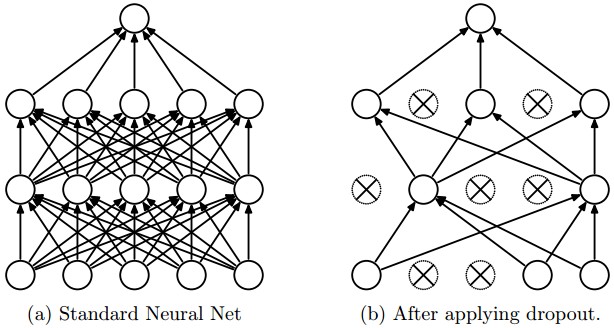
By doing this, the network is forced to increase redundancy - so that the same information can be represented even with a dramatic amount of data loss.
Dropout in Keras¶
keras.layers.Dropout(rate=p) will set a fraction of p of the inputs to the layer to 0.
Other options are:
| Dropouts | Functionality |
|---|---|
Dropout |
Removes a fraction of inputs |
AlphaDropout |
Removes inputs and keeps mean and variances |
GaussianDropout |
Multiplies inputs with Gaussian noise |
fig5

More robust at the price of longer training¶
These three all look like they might still be growing... Maybe if we "just" spend more time?
fig6

fig7
