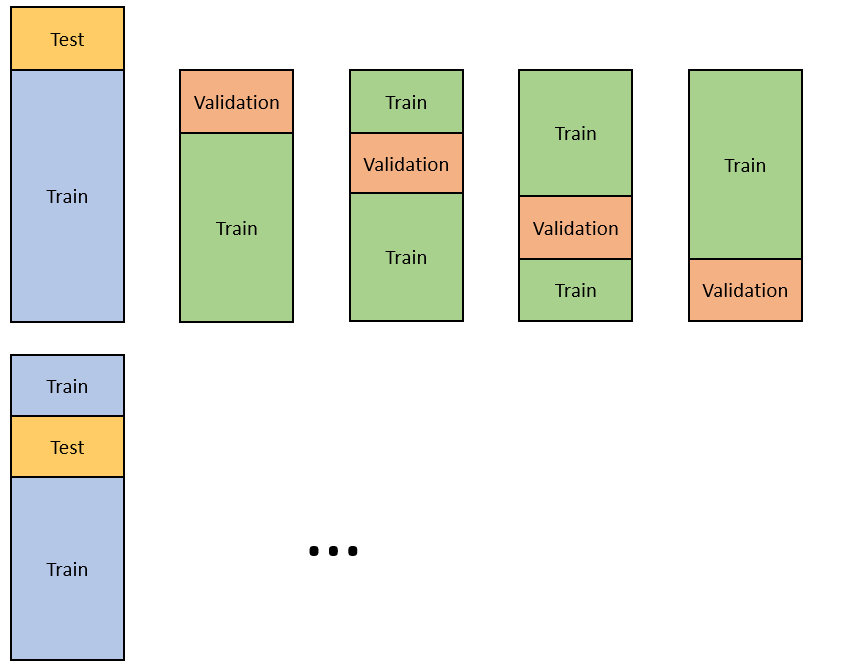
Time series and cross-validation¶
Low cross-validation error and high test (submission) error is usually a sign of over-fitting. Many models assume samples are drawn independently, and correlation between samples can be a problem.
We are here dealing with data that has a pretty high degree of row-wise correlation going on: if traffic is bad, many many taxis will be slower. The correlation arises from us essentially studying a time-series.
To deal with this, cross-validation on time-series takes on a slightly different shape: instead of drawing at random, time-series cross-validation splits time into chunks, and scores the next chunk based on training on everything preceding it.
In scikit-learn¶
scikit-learn implements time-series cross-validation in the model_selection.TimeSeriesSplit object. This can be a value for the cv parameter to a cross-validation model or function.
Nested cross-validation¶
When you are repeatedly using cross-validation to tune hyper-parameters to your model, you get data leakage: you are using the same data in training as you are using in validating.
To get better performance, the research community suggests nested cross-validation. It goes like this:
model = GridSearchCV(estimator, cv=5, n_jobs=-1)
scores = cross_val_score(model, cv=5, n_jobs=-1)cross_val_score splits the data into 5 parts, feeds 4 parts to the model.
GridSearchCV takes the 4 parts of the original data, splits into 5 parts, feeds 4 of those into the estimator.
For each hold-out set of the 5 outer folds, some best-performing estimator is found with a best score. These can be averaged, or further studied to get more accurate estimates of model performance.
Use these cross-validation scores for model selection between competing algorithms, then finally do a grid-search (inner loop) for hyper-parameter setting afterwards.