We have worked with one mean (one-sample T-tests), two means (two-sample T-tests), or several distinct means (ANOVA).
Now it is time to introduce the notion of predictors and models that depend on predictor variables.
We can see the cases we have already studied as specific cases where the predictors are variables that take on finitely many values:
One Mean
Predictor is (trivially and usually ignored) a constant value.
Two Means
Predictor takes two distinct values.
ANOVA
Predictor takes \(I\) distinct values.
Statistical Models
Definition
Given some set of predictor variables (aka independent v., explanatory v., covariate v., exposure v., manipulated v., input v., control v., exogenous v., regressor, risk factor, feature) \(X_1,\dots,X_n\) and some probabilistic model for error\(\epsilon\sim\mathcal{D}(X_1,\dots,X_n)\), an additive model specifies the values of some response variables (aka dependent v., explained v., predicted v., measured v., experimental v., outcome v., output v., endogenous v., criterion, regressand, target, label) \(Y\) in terms of a function applied to the predictors with the noise added:
\[
Y = f(X_1,\dots,X_n) + \epsilon
\]
It is customary that the distributions \(\mathcal{D}\) are chosen so that \(\EE[\epsilon]=0\) for any choice of predictors; if not, then the expected value could just be added to the function \(f\) for an equivalent model that has expected error 0.
We will also often have reason to worry about homoscedasticity and heteroscedasticity of the errors: the errors are homoscedastic if their variance does not depend on the predictors, and heteroscedastic when they do.
Statistical Models
We have seen models already that have predictor variables that take on two distinct values.
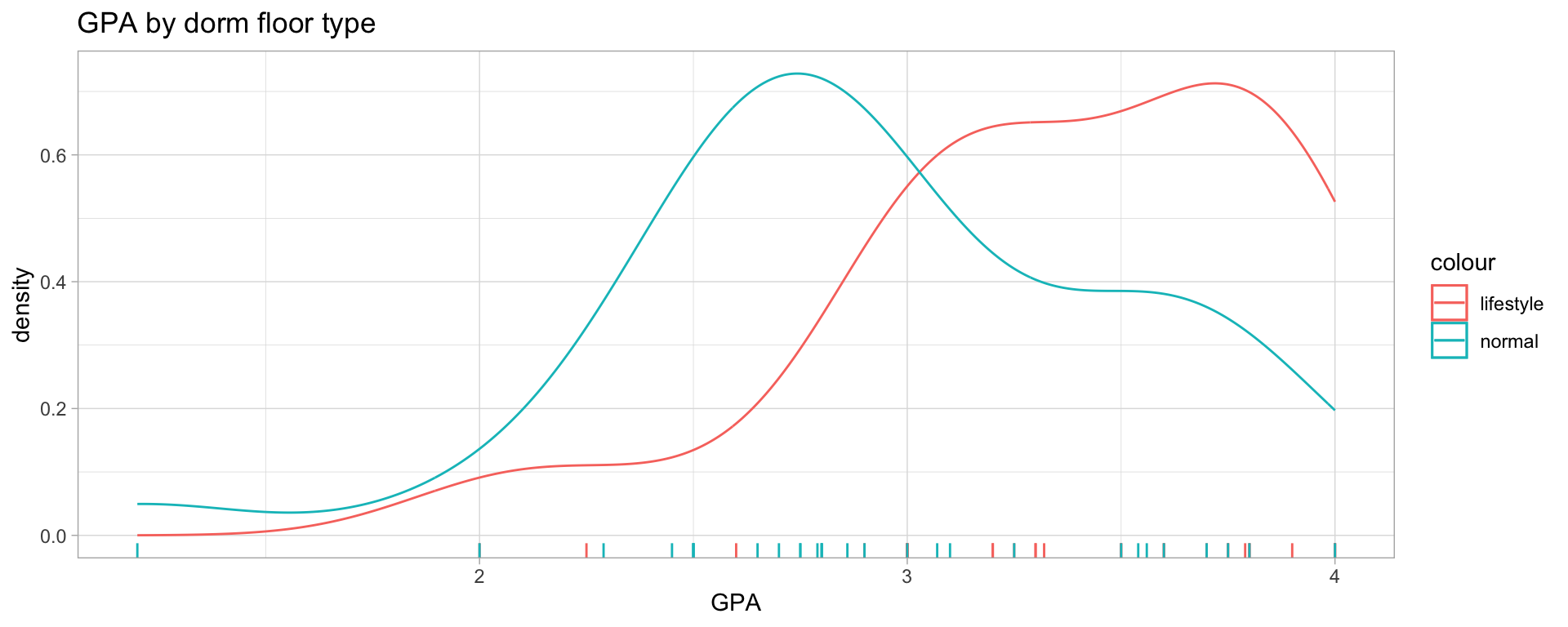
Recall the data on GPA by dorm floor from last lecture.
We can think of this data as a probabilistic model with predictor \(X=\{\text{lifestyle}, \text{normal}\}\) and response \(GPA\in[0,4]\).
Statistical Models
Our first step in analyzing this was with a two-sample T-test, an approach that assumes a normal error model, so that the complete model here would have been:
An alternative way to write the same model could be:
\[
GPA(X) \sim \mathcal{N}(\mu(X), \sigma^2)
\]
with the error terms taken as implicit.
The Simple Linear Regression Model
One step up in complexity from the functions of one or two distinct values we have seen previously would be a linear function1: \(y = \beta_0+\beta_1x\).
We define:
Definition
The simple linear regression model is an additive model with one predictor and one response connected by a linear function and homoscedastic independent normal errors.
with deterministic predictor \(x\) without randomness or measurement error, and randomly varying \(Y\).
The population regression line is the line of expected values \(y = \beta_0+\beta_1x\).
Exercise 12.9
Flow rate \(y\) (\(m^3/min\)) in a measurement device depends on the pressure drop \(x\) (inches of water) across the device’s filter.
For \(x\in[5,20]\), the variables follow a regression model with regression line \(y=-.12 + 0.095x\).
a. What is the expected change in flow rate associated with a 1-inch increase in pressure drop?
With a slope of \(0.095\), we expect for every \(1\) that is added to \(x\), we would add \(0.095\) to \(y\).
b. What change in flow rate can be expected when pressure drop decreases by 5 inches?
With a decrease of 5 inches, we would expect a change of \(\beta_1\cdot\Delta x=0.095\cdot(-5)=-.475\), so a decrease by \(.475\).
c. What is the expected flow rate for a pressure drop of 10 inches? A drop of 15 inches?
\(\EE[Y|x=10]= -.12+.095\cdot 10=0.830\) and \(\EE[Y|x=15]= -.12+.095\cdot 15=1.305\)
Exercise 12.9
d. Suppose \(\sigma=0.025\) and consider a pressure drop of 10 inches. Calculate \(\PP(Y>0.835)\) and \(\PP(Y>0.840)\).
Since for \(x=10\), we get the distribution \(Y\sim\mathcal{N}(0.830, 0.025^2)\), we may calculate \(\PP(Y>0.835) = 1-CDF_{\mathcal{N}(0.830,0.025^2)}(0.835) \approx 0.4207\) or 42.07%, and \(\PP(Y>0.840) = 1-CDF_{\mathcal{N}(0.830,0.025^2)}(0.840) \approx 0.3446\) or 34.46%.
e. Let \(Y_1\) be measured at \(x=10\) and \(Y_2\) at \(x=11\). Calculate \(\PP(Y_2 < Y_1)\).
We are sampling \(Y_1\sim\mathcal{N}(0.830, \sigma^2)\) and \(Y_2\sim\mathcal{N}(0.925, \sigma^2)\) independently, and need to compute the probability of \(Y_2<Y_1\).
\(Y_2 < Y_1\) precisely when \(0<Y_1-Y_2\), so we can consider the random variable \(Y_1-Y_2\sim\mathcal{N}(0.830-0.925, 2\sigma^2) = \mathcal{N}(-0.095, 2\cdot0.025^2)\) and look for the probability mass where this difference is \(>0\).
This leads us to compute the upper tail \(1-CDF_{\mathcal{N}(-0.095, 0.03535^2)}(0)\approx0.0036\) for a probability of \(0.36%\) for the lower observation exceeding the higher observation.
Estimating \(\beta_0\), \(\beta_1\), \(\sigma^2\)
Among all possible choices of straight line models that we could pick (\(\Omega = \underbrace{\RR}_{\beta_0} \times \underbrace{\RR}_{\beta_1} \times \underbrace{\RR_{\geq 0}}_{\sigma^2}\)), we need to find the best fit.
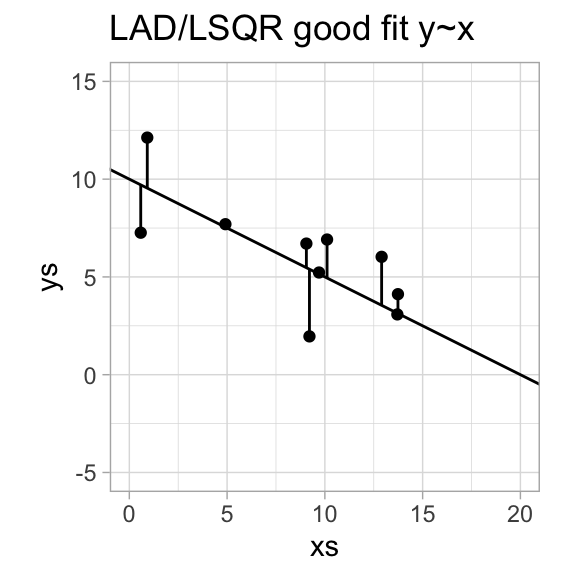
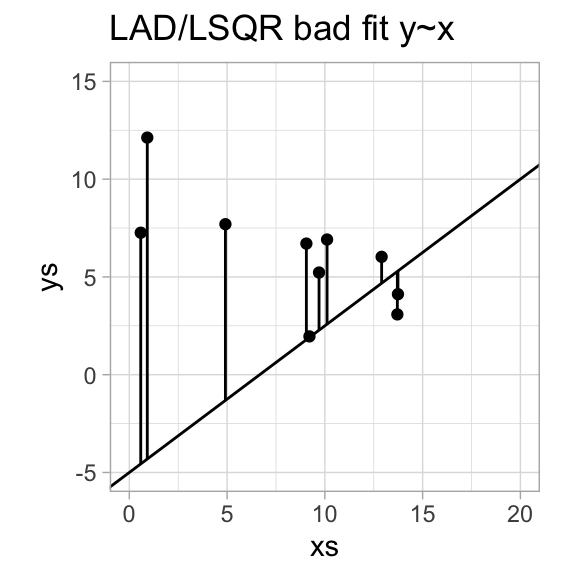
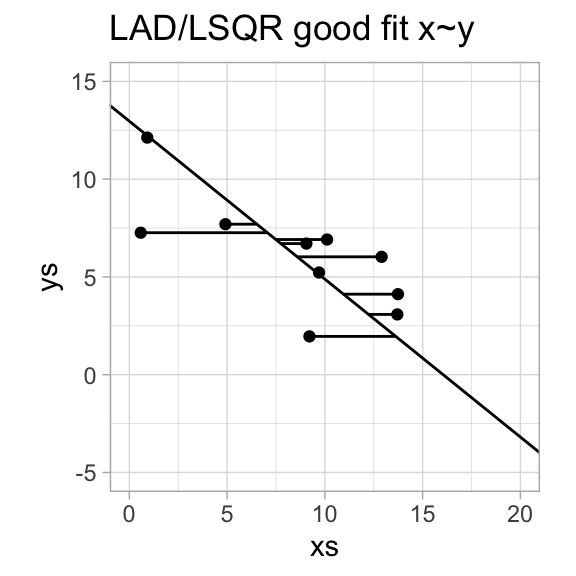
There are a number of ways to do this, but by far the most popular is the least squares method - partially because we then in most cases get a closed simple formula for the model parameters.
Measuring quality of fit
Least Absolute Deviations
Seek a regression function \(f\) that minimizes \(\sum_{i=1}^n|y_i-f(x_i)|\).
Iterative solutions with optimization methods.
Robust to outliers.
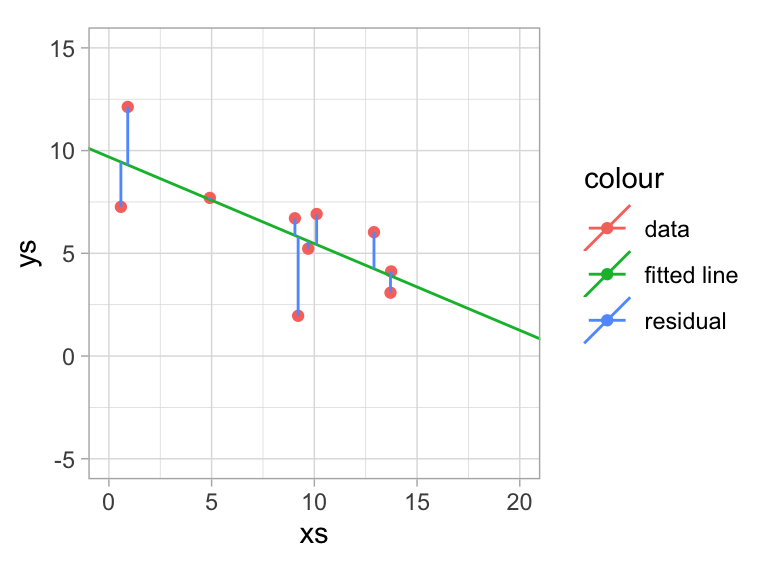
Least Squares
Seek a regression function \(f\) that minimizes \(\sum_{i=1}^n(y_i-f(x_i))^2\).
Unique (often) closed form solution.
Not robust.
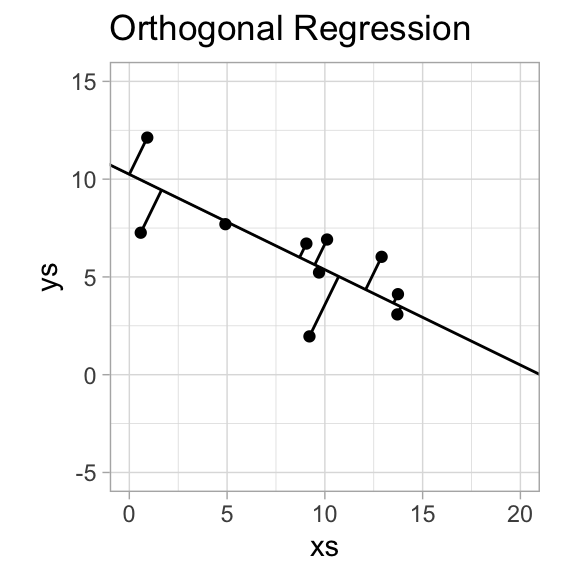
Orthogonal Regression
Seek a regression function \(f\) that minimizes shortest distance from data point to line.
We are trying to minimize the sum of squares of the residuals: \[
SSR =
\sum(y_i - \hat y_i)^2 =
\sum(y_i - f(x_i))^2 =
\sum(y_i - (b_0 + b_1x_i))^2
\]
As usual, we compute partial derivatives with respect to the parameters \(b_0, b_1\) and seek critical values:
This is a system of linear equations in two unknowns (\(b_0, b_1\)), called the normal equations. As long as not all \(x_i\) are equal to each other, the system has a unique solution which provides the least squares estimate.
These estimates can be computed without actually computing each residual, by using: \[
S_{xy} = \sum x_iy_i-\frac{\left(\sum x_i\right)\left(\sum y_i\right)}{n}
\quad
S_{xx} = \sum x_i^2-\frac{\left(\sum x_i\right)^2}{n}
\quad
b_1=\hat\beta_1=\frac{S_{xy}}{S_{xx}}
\]
Maximum Likelihood for Regression
(Exercise 12.23)
Find maximum likelihood estimates of \(\beta_0\) and \(\beta_1\) (and show that they are exactly what we derived).
Each \(Y_i\sim\mathcal{N}(\beta_0+\beta_1x_i, \sigma^2)\), so the joint likelihood is: \[
\begin{align*}
\mathcal{L}(\beta_0,\beta_1,\sigma^2|y_1,\dots,y_n) &=
\prod_i PDF_{\mathcal{N}(\beta_0+\beta_1x_i, \sigma^2)}(y_i) \\
&= \prod_i \frac{1}{\sqrt{2\pi\sigma^2}}\exp\left[-\frac{1}{2\sigma^2}(y_i-(\beta_0+\beta_1x_i))^2\right] \\
&\text{switching to log likelihood} \\
\ell(\beta_0,\beta_1,\sigma^2) &=
\sum_i-\frac{1}{2}\left(
\log(2\pi)+\log(\sigma^2)+\frac{1}{\sigma^2}(y_i-(\beta_0+\beta_1x_i))^2
\right) \\
&= -\frac{1}{2}\left(
n\log(2\pi)+n\log(\sigma^2)+\frac{1}{\sigma^2}\sum(y_i-(\beta_0+\beta_1x_i))^2
\right)
\end{align*}
\]
Extracting the factor \(-1/(2\sigma^2)\cdot 2\cdot (-1)\), we are left with the equations for critical points exactly matching the normal equations. So finding the MLEs proceeds identical to how we derived estimates from the normal equations before.
Estimating \(\sigma^2\)
Once we have estimated \(\hat\beta_0\) and \(\hat\beta_1\), we can compute fitted or predicted values \(\hat y_i = \hat\beta_0+\hat\beta_1x_i\). The residuals are the prediction errors \(e_i = y_i - \hat y_i\).
Key to estimating \(\sigma^2\) is a similar kind of separation of sources of variance as we saw in ANOVA.
The variance \(\VV[Y]\) comes in part from the slope of the line (spreading out the observations), and in part from the inherent variance \(\sigma^2\).
The residuals measure exactly the deviation that is not due to the slope of the regression line, so we may want to use the variance of the residuals to estimate \(\sigma^2\).
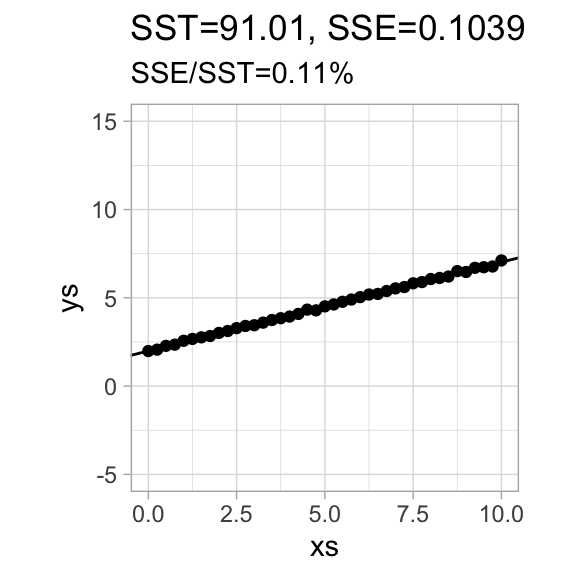
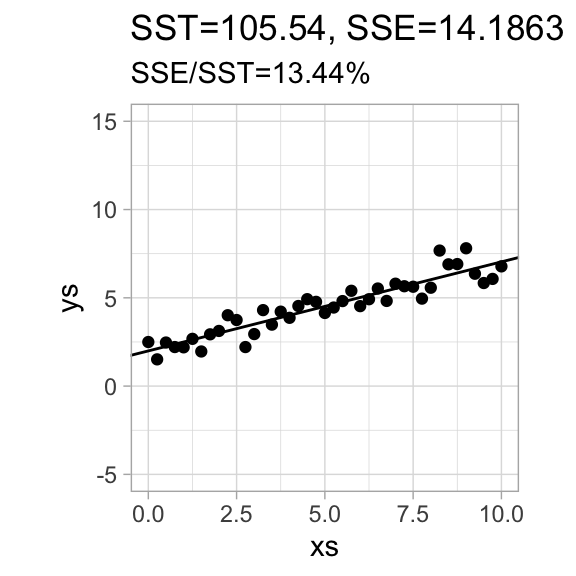
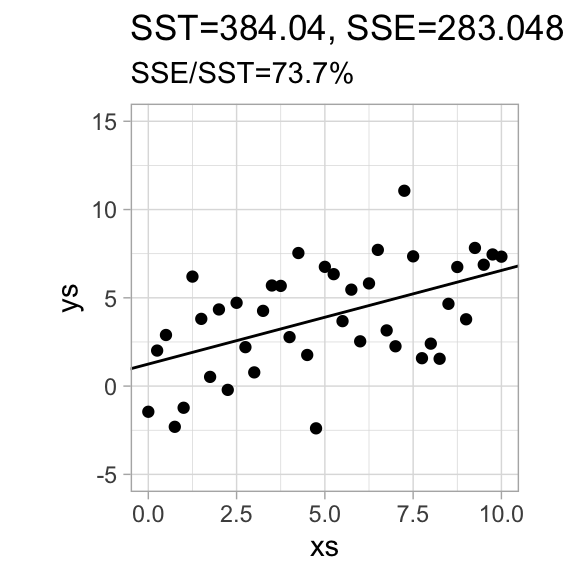
We define the coefficient of determination\(r^2 = 1 - \frac{SSE}{SST}\), the fraction of the total variance that is not explained by the variance of the residuals. The notation hints at a connection to correlations, which we will later see more about.
ANOVA Equation for Regression
(Exercise 12.24)
Write \(e_i=y_i-\hat y_i=y_i-(b_0+b_1x_i)\) for the residuals.
Often useful is the fact that \((\overline x, \overline y)\) is actually on the regression line directly, which we can see by computing:
\[
\hat\beta_0 + \hat\beta_1\overline x =
\overline y - \hat\beta_1\overline x + \hat\beta_1\overline x = \overline y
\]
Inferences about the slope
To build inferences (hypothesis tests and confidence intervals) about the slope \(\beta_1\) of a linear regression model, we will rephrase these results as claims about random variables.
We will not be working with random predictors here - the \(x_i\) are all deterministic, but instead of values \(y_i\) we will have random variables \(Y_i\) (and hence also \(\overline Y\) and \(S^2\)).
We note that \(S_{xY} = \sum(x_i-\overline x)(Y_i-\overline Y) = \sum Y_i(x_i-\overline x) - \overline Y\underbrace{\sum(x_i-\overline x)}_{=0}\).
Since the standard error for the estimator \(\hat\beta_1\) is \(\sigma/\sqrt{S_{xx}}\), and since the \(S^2=SSE/(n-2)\) estimator has \(n-2\) degrees of freedom, we get that:
The model utility test can equivalently be tested with an ANOVA approach - and doing this sets the stage for easier generalization to multilinear regression (not in scope for this course):