Many of our tests have focused on comparing means of groups:
Null Hypothesis Type
Test Type
\(H_0:\mu = \mu_0\)
One-sample T test
\(H_0:\mu_1 = \mu_2\)
Two-sample T test
We will next introduce the next step in this progression: comparing means for more than 2 subgroups of a set of observations.
Our setup thus is going to be that we have some collection of samples, each from a separate normal distribution, with the same variance for each sample. We will be interested in testing:
\(H_0:\mu_1 = \dots = \mu_I\) vs. the alternative that at least one pair of groups have different means.
Notation and Assumptions
For this, we will use the following notation:
\(X_{1,1},\dots,X_{I,J}\) are our observed random variables.
\(\overline{X}_{i,*} = \frac{1}{J}\sum_{j=1}^J X_{i,j}\), the group-wise sample means.
\(\overline{X}_{*,*} = \frac{1}{IJ}\sum_{i=1}^I\sum_{j=1}^J X_{i,j}\), the grand sample mean.
\(S_1^2,\dots,S_I^2\) are the sample variances of the groups \(1\) through \(I\).
Upper-case letters will denote random variables (or total sizes, for \(I\) and \(J\)), and lower-case letters are observations or realizations of those random variables.
Checking the assumptions
We have two important assumptions that we are making:
Each observation is normal.
All variances are equal.
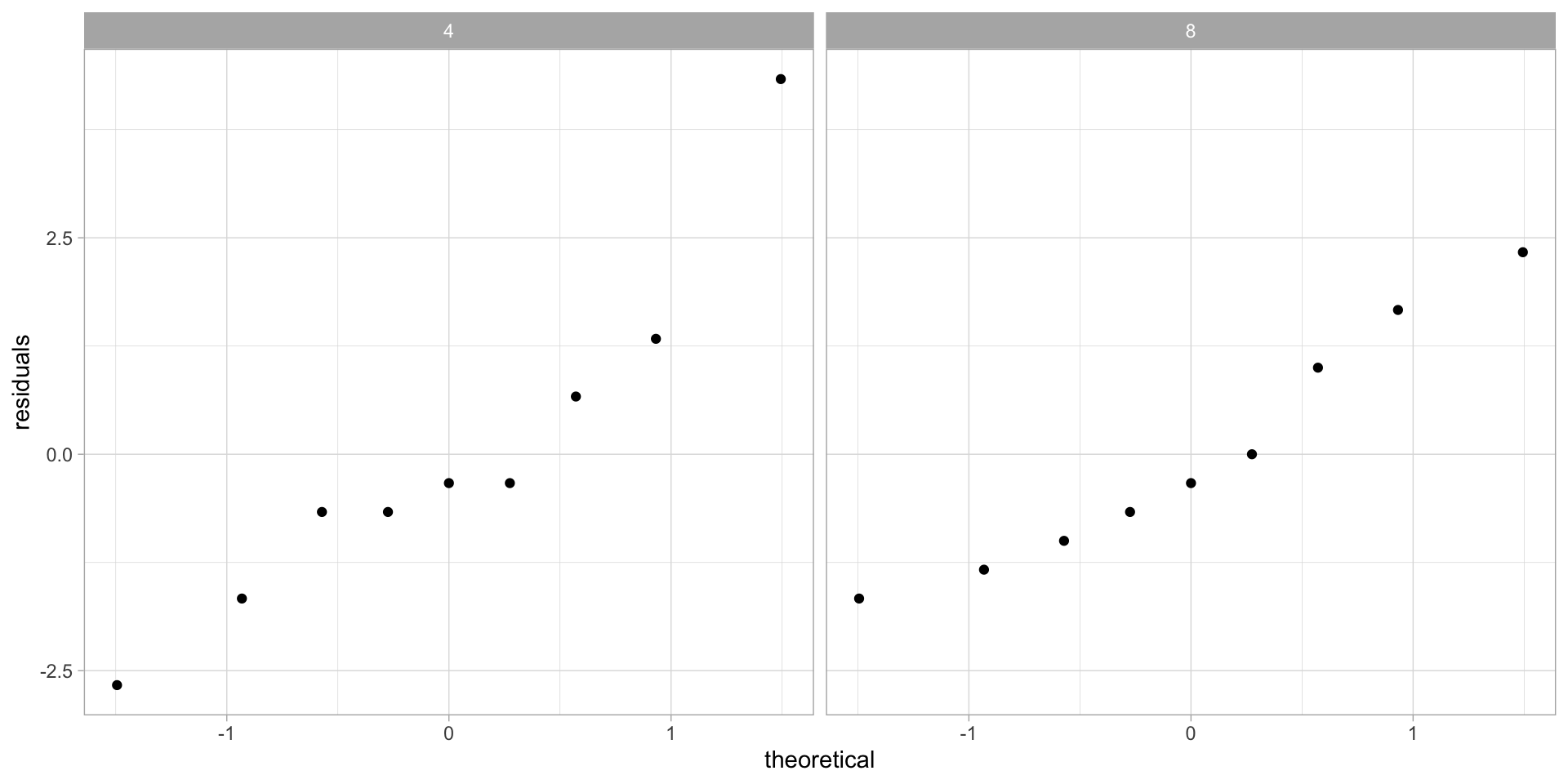
To check 1., we could use individual probability plots for each group. Alternatively, we can compute the residuals\(r_{i,j} = x_{i,j}-\overline{x}_{i,*}\), and check that all the residuals taken as one group form a normal distribution.
Running Example
Autistic and Neurotypical Peer-to-peer Information Sharing
CJ Crompton, D Ropar, CVM Evans-Williams, EG Flynn, S Fletcher-Watson, Autistic peer-to-peer information transfer is highly effective, Autism (2020) 24:7, doi:10.1177/1362361320919286
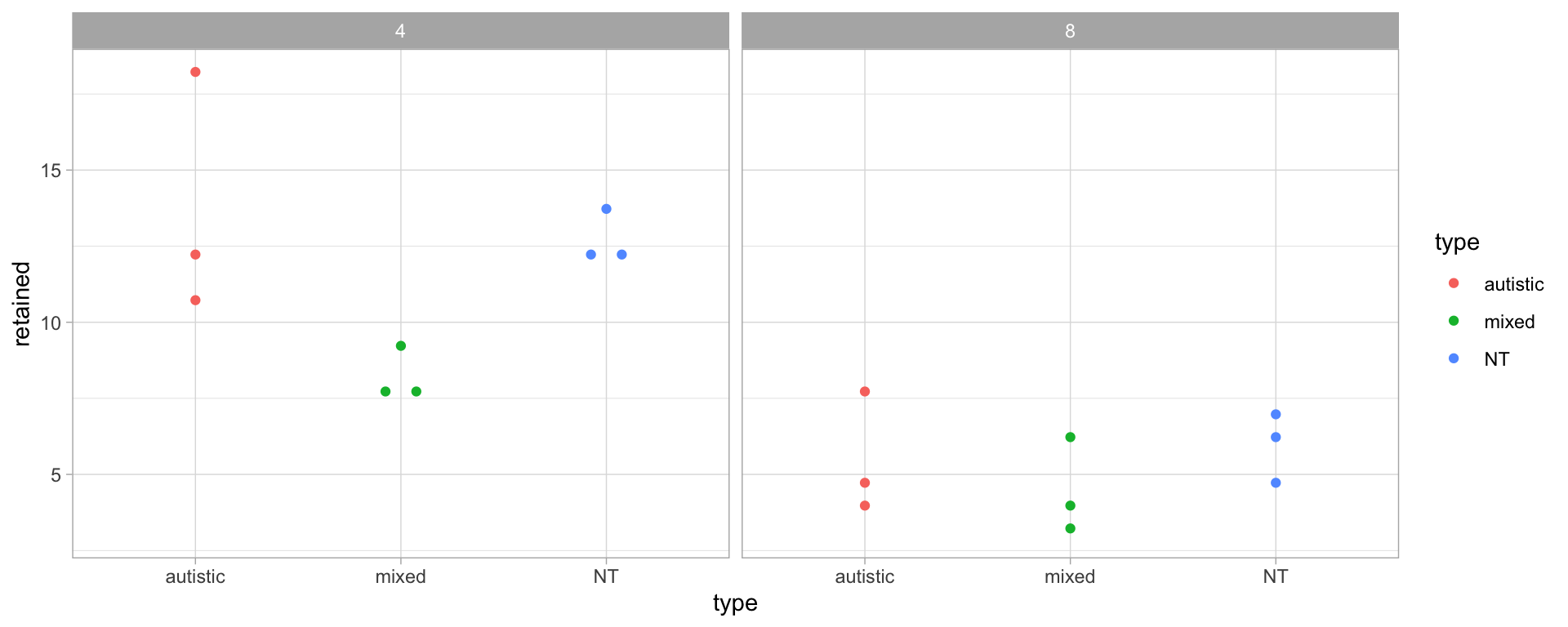
The research project recruited 9 groups of 8 participants to form “game of telephone” communication chains. 3 chains were only with autistic adults. 3 chains were only with neurotypical adults. 3 chains were alternating NT-autistic-NT-autistic-NT-autistic-NT-autistic. First person in each chain was told a complex and bizarre story by the researchers, and then each person in the chain re-told the story to the next person in the chain. At each step, they measured how many of the story details were retained.
After everything, they also measured by a self-reporting survey, their feelings of ease, enjoyment, success, friendliness, awkwardness.
Running Example
Autistic and Neurotypical Peer-to-peer Information Sharing
The number of retained story details (out of a total of 30) after each step were:
There are \(IJ\) terms in the sum that defines the SST, but they all include the term \(\overline{x}_{*,*}\), so there is one connecting equation for all of them.
SSE has \(I(J-1)\) degrees of freedom
There are \(IJ\) terms in the sum that defines the SSE, but there are \(I\) different group means, each of which defines a connecting equation, so the total degrees of freedom comes out to \(IJ-I = I(J-1)\).
SSTr has \(I-1\) degrees of freedom
There are \(I\) distinct variables \(\overline{x}_{i,*}\) in the sum that defines the SSTr, but the \(\overline{x}_{*,*}\) connects all of them in a connecting equation.
Variance Estimates
All three sum of squares can be used to estimate \(\sigma^2\) - the variance that according to our assumptions all the data sources share:
If the null hypothesis is false, then (in your homework you will) show that \(MSTr\) is larger than expected, so the ratio is larger and we can reject the null hypothesis with the upper tail of the \(F\) distribution.
The One-way ANOVA Test
One-way Analysis of Variance
Null Hypothesis
\(H_0:\mu_1=\dots=\mu_I\)
Test Statistic
\(F = \frac{MSTr}{MSE}\)
Rejection Region for Level \(\alpha\)
\(F > CDF_{F(I-1,I(J-1))}^{-1}(1-\alpha)\)
p-value
\(1-CDF_{F(I-1,I(J-1))}(F)\)
Running Example
Autistic and Neurotypical Peer-to-peer Information Sharing
We have established that the data seems to have normal errors (both after 4 steps and after 8 steps). Recall that we had:
step
\(I\)
\(J\)
\(\overline{X}_{1,*}\)
\(\overline{X}_{2,*}\)
\(\overline{X}_{3,*}\)
\(\overline{X}_{*,*}\)
\(S_1^2\)
\(S_2^2\)
\(S_3^2\)
4
3
3
12.7
8.3
13.7
11.6
1.2
0.6
3.8
8
3
3
6
4.3
5.7
5.3
1
1.5
2.1
For the one-way ANOVA test, we need to compute the entries in an ANOVA Table
The book recommends the Levene Test for testing for equal variances. This test is less sensitive than the Bartlett Test (which is what emerges from the likelihood ratio principle), and is done by running through a one-way ANOVA on the absolute values of the residuals.
Running Example, Equal Variances
Code
story.residuals %>%filter(step==4) %>%ungroup() %>%mutate(abs.residuals=round(abs(residuals),2)) %>%select(type, abs.residuals) %>% t %>%kable()story.residuals %>%filter(step==8) %>%ungroup() %>%mutate(abs.residuals=round(abs(residuals),2)) %>%select(type, abs.residuals) %>% t %>%kable()
Analysis of Variance Table
Response: abs.residuals
Df Sum Sq Mean Sq F value Pr(>F)
chain.type 2 1.1852 0.59259 1.1707 0.3722
Residuals 6 3.0370 0.50617
At the end, there seems to be less reason to doubt the equal variances assumption.
ANOVA as a modeling equation
There is a succinct way to describe the one-way ANOVA with a model equation:
This model equation can be rewritten by introducing \(\mu=\frac{1}{I}\sum_i \mu_i\), and modeling the deviations from the global mean as parameters \(\alpha_1,\dots,\alpha_I\). Then, with \(I+1\) parameters, that are connected by one equation we still have \(I\) independently determined parameters and get the model equation
A new null hypothesis then becomes \(\alpha_1=\alpha_2=\dots=\alpha_I=0\).
ANOVA as a linear model
Suppose now that we represent membership in group \(i\) by the \(i\)th unit vector, so that we can represent e.g. the running example data (seen to the left) by a matrix like the one on the right instead:
where the \(\beta_{i,j}\) are the one-hot encoded variables, so at most one of these \(\beta_{i,j}\) is non-zero (and therefore \(=1\)) at any given point.
Modeling Formulas
This specification of the ANOVA model using predictor variables and response variables is of core importance for using computational software1 to compute for us.
In R, it is a very common convention to write “\(Y\) is predicted by \(X\)” as Y ~ X (and if we expect \(Y=\beta_1 X_1+\beta_2 X_2\) we would write something like Y ~ X.1 + X.2)
ANOVA automated commands
In R
In R, ANOVAs are handled very similar to linear regression computations. Counter-intuitively, the command anova does not run an ANOVA model, but instead outputs the ANOVA table for a large class of possible models. Instead, the aov command runs a linear model with the expectation that it be an ANOVA model.
To use aov, first make sure that your data is in long shape - that is to say, values of interest in one column (say retained for the running example) and group membership in another column (say type for the running example).
Then an ANOVA analysis is performed by the aov command, which by default outputs the response as a truncated ANOVA table. To get a full ANOVA table, use the anova command on its output:
Code
model =aov(retained ~ type, story.last %>%filter(step==4))anova(model)
Analysis of Variance Table
Response: retained
Df Sum Sq Mean Sq F value Pr(>F)
type 2 48.222 24.1111 4.5208 0.06347 .
Residuals 6 32.000 5.3333
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
ANOVA automated commands
In Python
SciPy provides the command scipy.stats.f_oneway for performing one-way ANOVA tests. Each separate group is given as a separate argument for the function.