Hypothesis Testing: Background, Error Types
Significance and Power illustrated
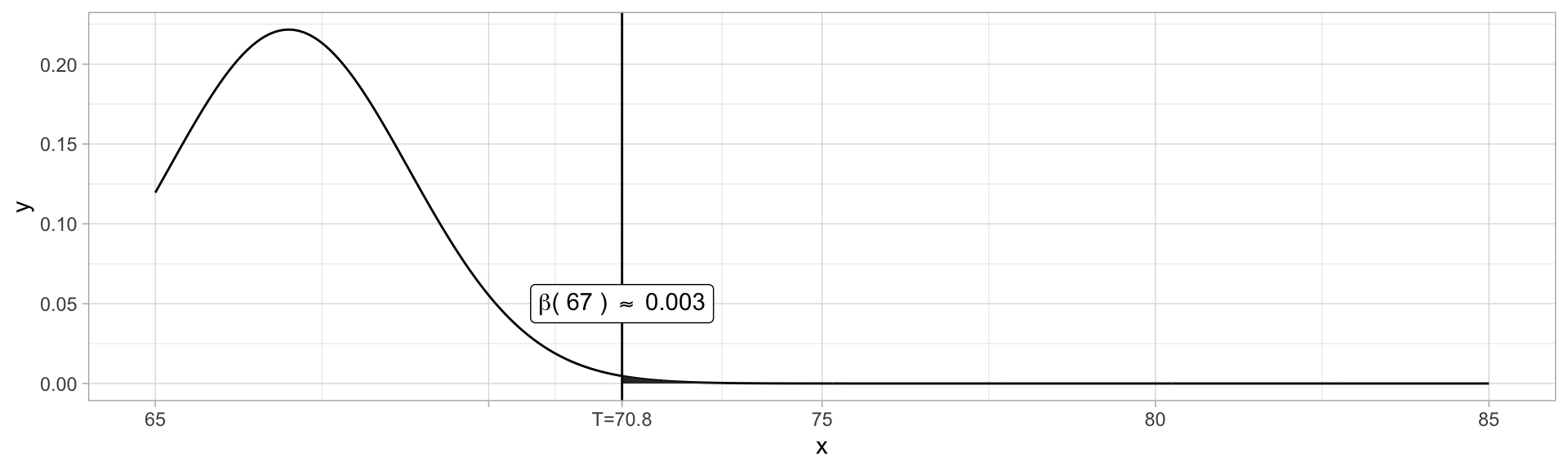
Suppose we know our test statistic \(X\sim\mathcal{N}(\mu,\sigma^2)\) for some known \(\sigma^2\), and unknown \(\mu\). Our null hypothesis is specified by \(H_0: \mu = \mu_0\), and our alternative hypothesis is specified as a subset of possible values for \(\mu\) as \(\mu < \mu_0\).
For instance, from Example 9.2, a known type of paint has drying time \(T\sim\mathcal{N}(75, 9^2)\). A new additive is proposed to decrease drying times, and the proposers believe this remains normally distributed with lower mean but retained variance.
We have collected \(T_1,\dots,T_{25}\) from test specimens. We expect \(\overline{T}\sim\mathcal{N}(\mu, 9^2/25\approx3.24)\). A rejection region \(\overline{x}\leq 70.8\) is suggested.
Code
library(tidyverse)
library(latex2exp)
theme_set(theme_light())
x.0 = 70.8
x.true = 75
tibble(x = seq(65, 85, length.out=1001),
y = dnorm(x, mean=x.true, sd=9/sqrt(25)),
ylo = ifelse(x<x.0, dnorm(x,mean=x.true,sd=9/sqrt(25)), 0)) %>%
ggplot(aes(x=x)) +
geom_line(aes(y=y)) +
geom_area(aes(y=ylo)) +
geom_vline(xintercept = x.0) +
annotate("label", x=70, y=0.05, label=TeX(paste("\\alpha \\approx", round(pnorm(x.0, mean=x.true, sd=9/sqrt(25)), 3)))) +
scale_x_continuous(breaks=c(65,70,x.0,75,80,85),
labels=c(65,"",TeX("T=70.8"),75,80,85))
x.true = 72
tibble(x = seq(65, 85, length.out=1001),
y = dnorm(x, mean=x.true, sd=9/sqrt(25)),
ylo = ifelse(x>x.0, dnorm(x,mean=x.true,sd=9/sqrt(25)), 0)) %>%
ggplot(aes(x=x)) +
geom_line(aes(y=y)) +
geom_area(aes(y=ylo)) +
geom_vline(xintercept = x.0) +
annotate("label", x=72, y=0.05, label=TeX(paste("\\beta(", x.true,") \\approx", round(1-pnorm(x.0, mean=x.true, sd=9/sqrt(25)), 3)))) +
scale_x_continuous(breaks=c(65,70,x.0,75,80,85),
labels=c(65,"",TeX("T=70.8"),75,80,85))
x.true = 70
tibble(x = seq(65, 85, length.out=1001),
y = dnorm(x, mean=x.true, sd=9/sqrt(25)),
ylo = ifelse(x>x.0, dnorm(x,mean=x.true,sd=9/sqrt(25)), 0)) %>%
ggplot(aes(x=x)) +
geom_line(aes(y=y)) +
geom_area(aes(y=ylo)) +
geom_vline(xintercept = x.0) +
annotate("label", x=72, y=0.05, label=TeX(paste("\\beta(", x.true,") \\approx", round(1-pnorm(x.0, mean=x.true, sd=9/sqrt(25)), 3)))) +
scale_x_continuous(breaks=c(65,70,x.0,75,80,85),
labels=c(65,"",TeX("T=70.8"),75,80,85))
x.true = 67
tibble(x = seq(65, 85, length.out=1001),
y = dnorm(x, mean=x.true, sd=9/sqrt(25)),
ylo = ifelse(x>x.0, dnorm(x,mean=x.true,sd=9/sqrt(25)), 0)) %>%
ggplot(aes(x=x)) +
geom_line(aes(y=y)) +
geom_area(aes(y=ylo)) +
geom_vline(xintercept = x.0) +
annotate("label", x=72, y=0.05, label=TeX(paste("\\beta(", x.true,") \\approx", round(1-pnorm(x.0, mean=x.true, sd=9/sqrt(25)), 3)))) +
scale_x_continuous(breaks=c(65,70,x.0,75,80,85),
labels=c(65,"",TeX("T=70.8"),75,80,85))


Significance and Power illustrated
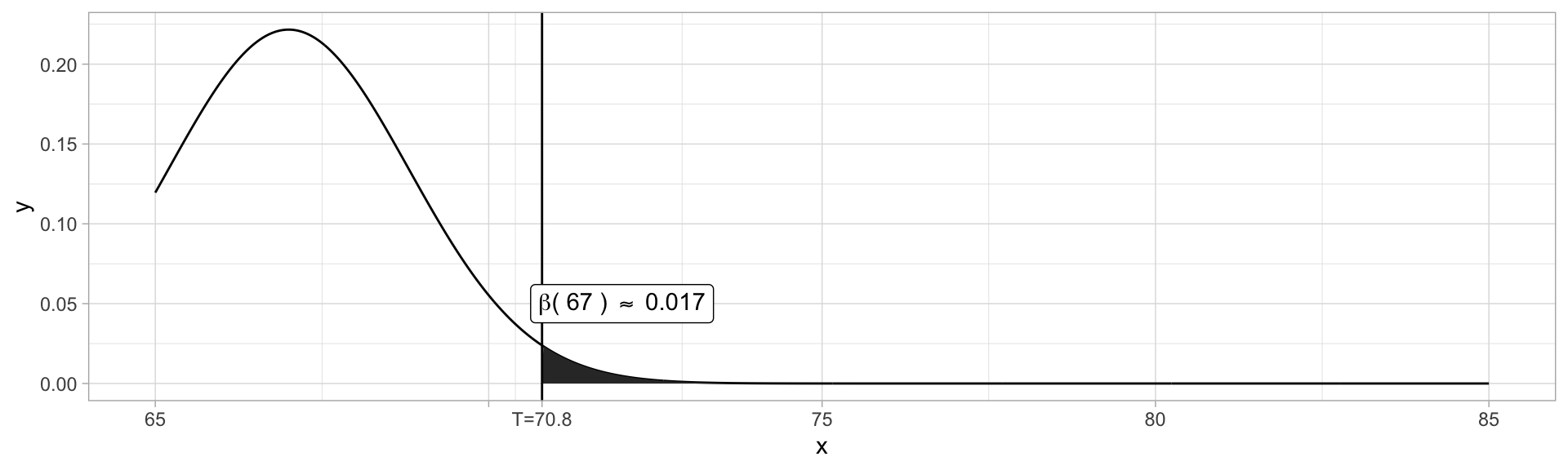
Suppose we know our test statistic \(X\sim\mathcal{N}(\mu,\sigma^2)\) for some known \(\sigma^2\), and unknown \(\mu\). Our null hypothesis is specified by \(H_0: \mu = \mu_0\), and our alternative hypothesis is specified as a subset of possible values for \(\mu\) as \(\mu < \mu_0\).
For instance, from Example 9.2, a known type of paint has drying time \(T\sim\mathcal{N}(75, 9^2)\). A new additive is proposed to decrease drying times, and the proposers believe this remains normally distributed with lower mean but retained variance.
We have collected \(T_1,\dots,T_{25}\) from test specimens. We expect \(\overline{T}\sim\mathcal{N}(\mu, 9^2/25\approx3.24)\). Given the very small \(\alpha\) using \(70.8\), another rejection region \(\overline{x}\leq 72\) is suggested.
Code
library(tidyverse)
library(latex2exp)
theme_set(theme_light())
x.0 = 72
x.true = 75
tibble(x = seq(65, 85, length.out=1001),
y = dnorm(x, mean=x.true, sd=9/sqrt(25)),
ylo = ifelse(x<x.0, dnorm(x,mean=x.true,sd=9/sqrt(25)), 0)) %>%
ggplot(aes(x=x)) +
geom_line(aes(y=y)) +
geom_area(aes(y=ylo)) +
geom_vline(xintercept = x.0) +
annotate("label", x=70, y=0.05, label=TeX(paste("\\alpha \\approx", round(pnorm(x.0, mean=x.true, sd=9/sqrt(25)), 3)))) +
scale_x_continuous(breaks=c(65,70,x.0,75,80,85),
labels=c(65,"",TeX("T=70.8"),75,80,85))
x.true = 72
tibble(x = seq(65, 85, length.out=1001),
y = dnorm(x, mean=x.true, sd=9/sqrt(25)),
ylo = ifelse(x>x.0, dnorm(x,mean=x.true,sd=9/sqrt(25)), 0)) %>%
ggplot(aes(x=x)) +
geom_line(aes(y=y)) +
geom_area(aes(y=ylo)) +
geom_vline(xintercept = x.0) +
annotate("label", x=72, y=0.05, label=TeX(paste("\\beta(", x.true,") \\approx", round(1-pnorm(x.0, mean=x.true, sd=9/sqrt(25)), 3)))) +
scale_x_continuous(breaks=c(65,70,x.0,75,80,85),
labels=c(65,"",TeX("T=70.8"),75,80,85))
x.true = 70
tibble(x = seq(65, 85, length.out=1001),
y = dnorm(x, mean=x.true, sd=9/sqrt(25)),
ylo = ifelse(x>x.0, dnorm(x,mean=x.true,sd=9/sqrt(25)), 0)) %>%
ggplot(aes(x=x)) +
geom_line(aes(y=y)) +
geom_area(aes(y=ylo)) +
geom_vline(xintercept = x.0) +
annotate("label", x=72, y=0.05, label=TeX(paste("\\beta(", x.true,") \\approx", round(1-pnorm(x.0, mean=x.true, sd=9/sqrt(25)), 3)))) +
scale_x_continuous(breaks=c(65,70,x.0,75,80,85),
labels=c(65,"",TeX("T=70.8"),75,80,85))
x.true = 67
tibble(x = seq(65, 85, length.out=1001),
y = dnorm(x, mean=x.true, sd=9/sqrt(25)),
ylo = ifelse(x>x.0, dnorm(x,mean=x.true,sd=9/sqrt(25)), 0)) %>%
ggplot(aes(x=x)) +
geom_line(aes(y=y)) +
geom_area(aes(y=ylo)) +
geom_vline(xintercept = x.0) +
annotate("label", x=72, y=0.05, label=TeX(paste("\\beta(", x.true,") \\approx", round(1-pnorm(x.0, mean=x.true, sd=9/sqrt(25)), 3)))) +
scale_x_continuous(breaks=c(65,70,x.0,75,80,85),
labels=c(65,"",TeX("T=70.8"),75,80,85))