Recall last lecture: using \(X_1,\dots,X_n\sim Uniform(0,\theta)\) we proposed using \(\hat\theta=2\overline{X}\) as an estimator, because \(\EE[X_i] = \theta/2\).
This is a first example of a generic approach:
Definition
Let \(X_1,\dots,X_n\sim\mathcal{D}\). The \(k\)th moment\(\mu_k=\EE[X^k]\). The \(k\)th sample moment is \(\frac{1}{n}\sum_i X_i^k\).
Suppose \(\mathcal{D}\) has a PMF/PDF with \(m\) parameters: \(f(x | \theta_1,\dots,\theta_m)\). The method of moment estimators\(\hat\theta_1,\dots,\hat\theta_m\) are obtained by equating the first \(m\) moments to their corresponding sample moments, and solving for \(\theta_1,\dots,\theta_m\)
Example: Uniform(a,b)
Let \(X_1,\dots,X_n\sim Uniform(a,b)\). We mean to estimate \(a\) and \(b\).
We know of the uniform distribution that \(\EE[X]=(a+b)/2\) and that \(\VV[X]=(b-a)^2/12\). So the method of moments approach calls on us to set up and solve:
We can ignore the solution \(\hat{b}=(\overline{X}-\sqrt{3(S^2-\overline{X}^2)})/2\) because the upper limit is not smaller than the mean.
Maximum Likelihood Estimation
Another, far more popular method for creating estimators is the maximum likelihood estimator.
Definition
Given a distribution \(\mathcal{D}\) with some parameters \(\mathbf{\theta}\) and PDF \(f(\mathbf{x} | \mathbf{\theta})\) (where both \(\mathbf{x}=(x_1,\dots,x_n)\) and \(\mathbf{\theta}=(\theta_1,\dots,\theta_m)\) may be vectors), and an observed outcome \(x_1,\dots,x_n\sim\mathcal{D}\), the likelihood function\(\mathcal{L}(\mathbf{\theta}|\mathbf{x})\) is \(f\) viewed as a function of \(\mathbf{\theta}\).
The maximum likelihood estimator\(\hat\theta = \arg\max_{\mathbf{\theta}}\mathcal{L}(\mathbf{\theta}|\mathbf{x})\) is the values of \(\theta_1,\dots,\theta_n\) that maximize the likelihood function. We abbreviate it as MLE.
Since logarithms1 are monotone, any maximum of \(\mathcal{L}\) is also a maximum of \(\log\mathcal{L}\). We often use \(\ell=\log\mathcal{L}\).
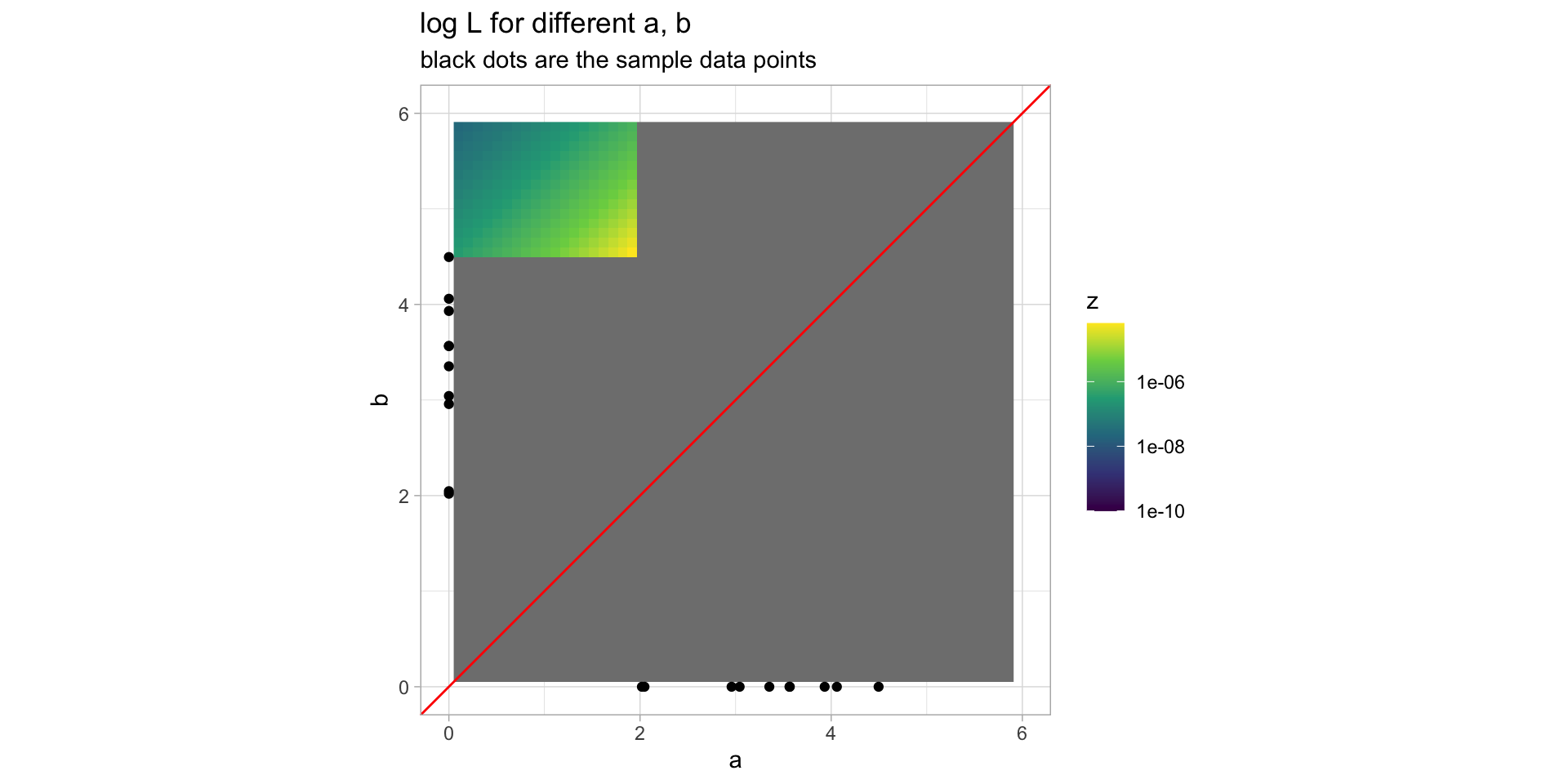
Example: Uniform(a,b)
Let \(X_1,\dots,X_n\sim Uniform(a,b)\). We mean to estimate \(a\) and \(b\).
library(tidyverse)xs =runif(10, 2, 4.5)L =function(a,b) {ifelse(a <min(xs), ifelse(max(xs) < b,ifelse(a < b,1/(b-a)^length(xs) ,0) ,0) ,0)}gx =seq(0,10, length.out=100)gy =seq(0,10, length.out=100)gg =expand.grid(x=gx, y=gy) %>%mutate(z =L(x,y))ggplot(gg, aes(x=x,y=y)) +geom_raster(aes(fill=z)) +scale_x_continuous(breaks=c(0,2,4,6), limits=c(0,6)) +scale_y_continuous(breaks=c(0,2,4,6), limits=c(0,6)) +scale_fill_viridis_c(trans="log10") +xlab("a") +ylab("b") +labs(title="log L for different a, b", subtitle="black dots are the sample data points") +geom_abline(color="red") +geom_point(data=tibble(x=xs), aes(x=x, y=0)) +geom_point(data=tibble(x=xs), aes(x=0, y=x)) +coord_equal() +theme_light()
To maximize it, we need to look for critical points and boundary points.
\[
\begin{align*}
\frac{d}{da}\frac{1}{(b-a)^n} &= \frac{n}{(b-a)^{n+1}} &
\frac{d}{db}\frac{1}{(b-a)^n} &= \frac{-n}{(b-a)^{n+1}}
\end{align*}
\] This tells us there will be no critical points in the defined region.
So it remains to look along the boundary.
Example: Uniform(a,b)
Let \(X_1,\dots,X_n\sim Uniform(a,b)\). We mean to estimate \(a\) and \(b\).
So the derivative along the horizontal boundary is always positive, and the derivative along the negative boundary is always negative. Neither is ever actually equal to 0.
The one remaining possible point for an extreme value is the point \((\min x_i, \max x_i)\), which turns out to actually hold the maximum likelihood.
Recall our \(Uniform(0,\theta)\) example
The two estimators we started with then were \(\theta=2\overline{X}\) and \(\theta=\max X\) - precisely the Method of Moments and the Maximum Likelihood estimators we just derived here.
Just like in the previous example, our MLE is biased and may need correction.
Another MLE: \(Exponential(\lambda)\)
Recall the exponential distribution: \(f(x|\lambda) = \lambda e^{-\lambda x}\). A random sample \(X_1,\dots,X_n\sim Exponential(\lambda)\) has joint likelihood function
By multiplying by appropriate powers of \(\sigma^2\) (which is sure to be \(>0\)), the first equation yields \(\hat\mu=(\sum x_i)/n\) and the second equation yields \(\hat\sigma^2=(\sum(x_i-\mu)^2)/n\).
Another MLE: \(Poisson(\lambda)\)
Suppose \(X_1,\dots,X_n\sim Poisson(\lambda)\). Their joint PMF (and thus likelihood) is
Which yields the estimator \(\hat\lambda = \overline{X}\).
Another MLE: Poisson Process
Suppose a region is subdivided into disjoint sample regions \(R_1,\dots,R_n\) and observations (eg counting plants of some fixed species) made so that \(X_1\sim Poisson(\lambda\cdot area(R_1)), \dots, X_n\sim Poisson(\lambda \cdot area(R_n))\).
Finding the critical point yields our MLE \(\hat\lambda = (\sum x_i)/(\sum area(R_i))\).
Another MLE: Poisson Process through distance to nearest neighbor
Instead of counting quadrants (as the process on the previous slide is called), we could pick \(n\) points at random in the domain, and for each of them measure the distance to the nearest observation. Write \(y_i\) for this distance from the \(i\)th point to the nearest observation.
\[
\begin{multline*}
CDF(y) = \PP(Y\leq y) = 1-\PP(Y > y) = \\
1-\PP(\text{no plants in a circle of radius $y$})
\end{multline*}
\]
With the point process from the previous slide, we can compute this probability: \[
\PP(Y > y) = PMF_{Poisson(\lambda\cdot area)}(0) = \frac{(\lambda\pi y^2)^0 e^{-\lambda\pi y^2}}{0!}
\]
So \(CDF(y) = 1-e^{-\lambda\pi y^2}\), and \(PDF(y) = 2\pi\lambda ye^{-\lambda\pi y^2}\) for \(y\geq 0\).
Another MLE: Poisson Process through distance to nearest neighbor
We measure \(Y_i\), the distance to the nearest observation from the randomly chosen point \(x_i\). We have found \(CDF(y) = 1-e^{-\lambda\pi y^2}\), and \(PDF(y) = 2\pi\lambda ye^{-\lambda\pi y^2}\) for \(y\geq 0\).
From this we get the MLE \(\hat\lambda = \frac{n}{\pi\sum y_i^2}\) or the ratio (number of plants observed)/(total area sampled).
Why we like MLEs - some properties that hold
Theorem
Let \(\hat\theta_1,\dots,\hat\theta_m\) be MLEs of the parameters \(\theta_1,\dots,\theta_m\).
Then the MLE of any function \(h(\theta_1,\dots,\theta_m)\) of these parameters is the function applied to the MLEs \(h(\hat\theta_1,\dots,\hat\theta_m)\).
We know the MLE for \(\sigma^2\) for a normal distribution - so we can directly write out the MLE for \(\sigma\):
It is, of course, a biased estimator. There are no guarantees that MLEs will be unbiased - and on top of that, Jensen’s inequality tells us that if we had an unbiased estimator for \(\sigma^2\), merely taking the square root would not give us an unbiased estimator of \(\sigma\).
Why we like MLEs - large-sample behavior
Theorem
Under very general conditions, for lage sample sizes, the MLE \(\hat\theta\) of any parameter \(\theta\) is…
…close to \(\theta\) (consistent estimator)
…approximately unbiased
…approximately MVUE
Homework Solutions
2.88: Nicholas Basile
\(0.8^3 = 0.512\)
\[
\begin{align*}
1 &| 1 1 1 \\
1 &| 0 1 1 & \text{1 flip would result in a 0} \\
1 &| 0 0 1 & \text{2 flips would result in a 1} \\
1 &| 1 0 1 & \text{3 flips would result in a 0}
\end{align*}
\] So we calculate \(0.8^3 + 3\cdot(0.8\cdot 0.2^2) = 0.608\).
Events:
A : 1 is transmitted
B : 1 is received
\(\PP(A|B) = \frac{\PP(B|A)\PP(A)}{\PP(B)}\). By b. we know \(\PP(B|A)=0.608\).
\(\PP(A) = 0.7\) was given in the question.
\[
\begin{multline*}
\PP(B) = \PP(B|1)\cdot 0.7+\PP(B|0)\cdot 0.3 = \\
= 0.608\cdot 0.7 + \color{SteelBlue}{(3\cdot(0.8^2\cdot 0.2)+0.2^3)}\cdot 0.3 = \\
= 0.5432
\end{multline*}
\] where the segment is computed analogously to b. but for the case where a 0 is received.
These sets of digit sum to: 6 (1x), 7 (1x), 8 (2x), 9 (3x), 10 (4x), 11 (4x), 12 (5x), 13 (4x), 14 (4x), 15 (4x), 16 (1x), 17 (1x) and 18 (1x). The probability of each outcome is the # of times divided by 35.
import collectionsoutcomes = {tuple(sorted((a,b,c))) for a inrange(1,8) for b inrange(1,8) for c inrange(1,8) if (a!=b) and (a!=c) and (b!=c)}W =list(map(sum, outcomes))Wcounts = collections.Counter(W)mu =sum([k*Wcounts[k]/len(outcomes) for k in Wcounts])s2 =sum([(k-12)**2*Wcounts[k]/len(outcomes) for k in Wcounts])print(f"mu = {mu}\t\ts2 = {s2}")