A parameter of a distribution of a random variable is some numeric property of the distribution. Often (but not always), these are the values that determine the shape of the distribution itself.
A statistic of a set of observed values assumed to come from some fixed (but possibly unknown) distribution is a numeric value calculable from the sample values.
A point estimate of a parameter \(\theta\) is a statistic with the intention of using it as a sensible value for \(\theta\). The chosen statistic is the point estimator.
Some familiar point estimators
Estimator
Parameter
Assumed distribution
\(\overline{X}=\frac{1}{N}\sum_{i=1}^N X_i\)
\(\EE[X]\)
almost any, because of the central limit theorem
\(\hat{p}=X/n\)
\(p\)
\(Binomial(n,p)\)
\(\frac{1}{N}\sum_{i=1}^N(X_i-\overline{X})^2\)
\(\VV[X]\)
almost any
\(\frac{1}{N-1}\sum_{i=1}^N(X_i-\overline{X})^2\)
\(\VV[X]\)
almost any
Quality of an estimator
Definition
The mean squared error (MSE) of an estimator \(\hat\theta\) estimating a parameter \(\theta\) is \(\EE[(\hat\theta-\theta)^2]\).
Also somewhat commonly used is the mean absolute error (MAE) \(\EE[|\hat\theta-\theta|]\), but the MSE is much easier mathematically, in part because of the bias-variance tradeoff.
Bias-Variance Tradeoff
Theorem
The mean squared error decomposes into one variance of the estimator term, and one term for the squared bias of the estimator:
To prove this theorem, first observe that \(\VV[Y]=\EE[Y^2]-(\EE[Y])^2\) implies that \(\EE[Y^2]=\VV[Y]+(\EE[Y])^2\).
Now, set \(Y=\hat\theta-\theta\) to be the estimation error. \(\EE[Y^2]\) is the MSE. The remaining term is formulated in terms of \(\EE[Y]=\EE[\hat\theta-\theta]=\EE[\hat\theta]-\theta\) since \(\theta\) is not a random variable1.
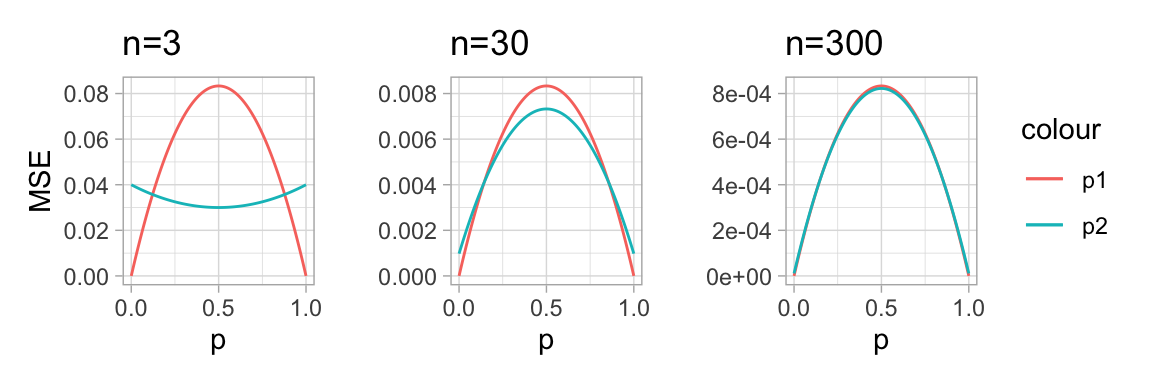
A tale of two estimators
Suppose \(X\sim Binomial(n,p)\) with \(n\) known and \(p\) unknown.
Let \(\hat{p}_1 = X/n\) and let \(\hat{p}_2 = (X+1)/(n+2)\). The effect of the changes in \(\hat{p}_2\) is to nudge the resulting estimate closer to \(0.5\), especially for extreme samples (almost nu successes; almost all successes).
There might not be any universally best estimator.
So maybe we need to restrict our class of estimators. If we choose to study only unbiased estimators, then \(MSE = \VV\), making it easier to optimize.
Definition
A point estimator \(\hat\theta\) of some parameter \(\theta\) is said to be unbiased if \(\EE[\hat\theta]=\theta\).
The bias of an estimator is the difference \(\EE[\hat\theta]-\theta\).
Some unbiased estimators
\(\hat\theta\)
\(\theta\)
Distribution
\(\overline{X}\)
\(\EE[X]\)
all
\(\hat{p}=X/n\)
\(p\)
\(Binomial(p,n)\)
Some biased estimators
\(\hat\theta\)
\(\theta\)
Distribution
\(\max X\)
\(b\)
\(Uniform(a,b)\)
\(\frac{1}{n}\sum(x_i-\mu_X)^2\)
\(\VV\)
all
\(\overline{X}\) is unbiased
Let \(X_1,\dots,X_n\sim\mathcal{D}\) for some distribution \(\mathcal{D}\) with expected value \(\EE[X_i]=\mu\). We compute:
\(\frac{1}{n}\sum(X_i-\overline{X})^2\) is biased (1/2)
Recall that \(\EE[X^2] = \VV[X] + \EE[X]^2\). We can show \(\frac{1}{n}\sum(X_i-\overline{X})^2 = \frac{1}{n}\sum_i(X_i^2 - \overline{X}^2)\). We compute:
Once we see the expected value of the estimator, it is easy to write down an unbiased estimator. Just multiply both sides with \(n/(n-1)\) yielding the usual unbiased estimator \(S^2 = \frac{1}{n-1}\sum(X_i^2-\overline{X}^2)\).
…but unbiased variance ≠ smallest MSE variance
One useful fact about chi-square variables is that \((n-1)S^2/\sigma^2\sim\chi^2(n-1)\). \(\chi^2(n-1)\) has mean \(n-1\) and variance \(2(n-1)\). Write \(X^2 = (n-1)S^2/\sigma^2\).
Consider all estimators \(S_c^2 = c\sum_i(X_i^2-\overline{X}^2)\). Notice that \(S_c^2 = (n-1)S^2c = \sigma^2X^2c\).
Expected value \(\EE[S_c^2]=\EE[\sigma^2X^2c]=\sigma^2\EE[X^2]c=\sigma^2(n-1)c\). Thus the bias is \(\sigma^2(n-1)c-\sigma^2\)
Since \(\sqrt\) is concave, \(\EE[\sqrt{S^2}] < \sigma\) and thus \(\sqrt{S^2}\) is a biased estimator of the standard deviation.
Minimum Variance Unbiased Estimators (MVUE)
Let’s soldier on and focus on unbiased estimators. Among these, the bias term in \(MSE\) vanishes, and so a minimum MSE unbiased estimator is one with minimum variance.
Example: the continuous German Tank Problem
Suppose \(X_1,\dots,X_n\sim Uniform(0,\theta)\). Our challenge is to estimate the value of \(\theta\) based on observations of the \(X_i\).
Idea: use the mean
The expected value of a \(X\sim Uniform(0,\theta)\) is
(this is an instance of the Method of Moments that we will meet later)
Idea: use the max
If we actually observe some value \(x\), then certainly \(\theta\geq x\), because the probability density is 0 outside the support.
So maybe \(\max\{X_i\}\) could work?
Aside: Order Statistics
To understand the max, we need a bit more theory to get it right - we need to know about order statistics.
Given \(X_1,\dots,X_n\sim\mathcal{D}\), write \(X_{(j)}\) for the \(j\)th biggest value among the \(X_i\), so that \(X_{(1)}\leq X_{(2)}\leq\dots\leq X_{(n)}\).
We will derive the PDF for \(X_{(j)}\) based on the PDF and CDF of \(\mathcal{D}\) (assuming that \(\mathcal{D}\) is a continuous distribution)
Let \(\delta x\) be a small value, so that the interval \((x, x+\delta x]\) is small enough for it to be unlikely to contain two of the \(X_i\). We split \(\RR\) into three components:
\(\color{Teal}{(-\infty, x]}\) with \(\PP = CDF(x)\)
\(\color{DarkMagenta}{(x, x+\delta x]}\) with \(\PP \approx PDF(x)\cdot\delta x\)
\(\color{GoldenRod}{(x+\delta x, \infty)}\) with \(\PP = 1-CDF(x+\delta x)\)
The middle interval contains \(X_{(j)}\) precisely if the first interval contains \(j-1\) of the \(X_i\), the middle interval contains exactly \(1\) of the \(X_i\), and the last interval contains \(n-j\) of the \(X_i\).
Aside: Order Statistics
This setup - three classes, prescribed # of elements falling in each, fixed probabilities for each class - is exactly the setup for the multinomial distribution (ch. 5.1). So we can write down the probability
So \(\max\{X_i\}\) is not unbiased - however, \(\frac{n+1}{n}\theta\) is.
MVUE - Continuous German Tank
Since both \(2\overline{X}\) and \(\frac{n+1}{n} X_{(n)}\) are unbiased, we only need to compare their variances. We know (or can look up) that the variance of \(Uniform(0,\theta)\) is \(\theta^2/12\).
For \(n>2\), we get that the bias-adjusted maximum has lower variance - and it can be shown that this is true for all other possible unbiased estimators.
Precision for estimators: Standard Error
Definition
The standard error of an estimator \(\hat\theta\) is its standard deviation \(\sigma_{\hat\theta} = \sqrt{\VV[\hat\theta]}\).
If this standard error requires estimated quantities, using estimates yields the estimated standard error\(s_{\hat\theta}\) or \(\hat\sigma_{\hat\theta}\).
Example: standard error of sample proportion
(Exercise 7.2) A sample of 20 students turned out to have owned Texas Instruments (T), Hewlett-Packard (H), Casio (C) or Sharp (S) calculators:
T T H T C T T S C H S S T H C T T T H T
Estimate \(\PP(\text{student owns TI})\).
T: 10, H: 4, C: 3, S: 3
We calculate \(\hat{p} = \#T/n = 10/20 = 1/2\).
We know that the binomial distribution has \(\VV=pq/n\), so \(s_{\hat{p}} = \sqrt{\hat\VV} = \sqrt{(1/2\cdot 1/2) / n} = \sqrt{1/80} \approx 0.1118 = 11.18\%u\).
Bootstrap estimation of standard errors
You might have an estimator that is difficult or complicated to analyze. Computers can help, using the bootstrap method.
Basic idea
Treat the sample you have as an empiric random distribution.
Draw new samples at random from the empiric distribution.
Study whatever you need to know about the sample distribution from these new samples.