Folders
Files
{kind=link}
DESCRIPTION
index.html
next_motif.gif
{kind=link}
PACKAGES
previous_motif.gif
{kind=link}
R-logo.gif
{kind=link}
Simple_0.6.tar.gz
Simple_0.6.zip
simpleR.R
stat.html
stat001.gif
{kind=link}
stat001.html
stat002.gif
{kind=link}
stat002.html
stat003.gif
{kind=link}
stat003.html
stat004.gif
{kind=link}
stat004.html
stat005.gif
{kind=link}
stat005.html
stat006.gif
{kind=link}
stat006.html
stat007.gif
{kind=link}
stat007.html
stat008.gif
{kind=link}
stat008.html
stat009.gif
{kind=link}
stat009.html
stat010.gif
{kind=link}
stat010.html
stat011.gif
{kind=link}
stat011.html
stat012.gif
{kind=link}
stat012.html
stat013.gif
{kind=link}
stat013.html
stat014.gif
{kind=link}
stat014.html
stat015.gif
{kind=link}
stat015.html
stat016.gif
{kind=link}
stat016.html
stat017.gif
{kind=link}
stat017.html
stat018.gif
{kind=link}
stat018.html
stat019.gif
{kind=link}
stat019.html
stat020.gif
{kind=link}
stat020.html
stat021.gif
{kind=link}
stat021.html
stat022.gif
{kind=link}
stat022.html
stat023.gif
{kind=link}
stat023.html
stat024.gif
{kind=link}
stat024.html
stat025.gif
{kind=link}
stat025.html
stat026.gif
{kind=link}
stat026.html
stat027.gif
{kind=link}
stat028.gif
{kind=link}
stat029.gif
{kind=link}
stat030.gif
{kind=link}
stat031.gif
{kind=link}
stat032.gif
{kind=link}
stat033.gif
{kind=link}
stat034.gif
{kind=link}
stat035.gif
{kind=link}
stat036.gif
{kind=link}
stat037.gif
{kind=link}
stat038.gif
{kind=link}
stat039.gif
{kind=link}
stat040.gif
{kind=link}
stat041.gif
{kind=link}
stat042.gif
{kind=link}
stat043.gif
{kind=link}
stat044.gif
{kind=link}
stat045.gif
{kind=link}
stat046.gif
{kind=link}
stat047.gif
{kind=link}
stat048.gif
{kind=link}
stat049.gif
{kind=link}
stat050.gif
{kind=link}
stat051.gif
{kind=link}
stat052.gif
{kind=link}
stat053.gif
{kind=link}
stat054.gif
{kind=link}
stat055.gif
{kind=link}
stat056.gif
{kind=link}
stat057.gif
{kind=link}
stat058.gif
{kind=link}
stat059.gif
{kind=link}



11 Two-sample tests
Two-sample tests match one sample against another. Their implementation in R is similar to a one-sample test but there are differences to be aware of.11.1 Two-sample tests of proportion
As before, we use the command prop.test to handle these problems. We just need to learn when to use it and how.
Example: Two surveys
A survey is taken two times over the course of two weeks. The pollsters wish to see if there is a difference in the results as there has been a new advertising campaign run. Here is the data
A survey is taken two times over the course of two weeks. The pollsters wish to see if there is a difference in the results as there has been a new advertising campaign run. Here is the data
The standard hypothesis test is H0: p1 = p2 against the alternative (two-sided) H1: p1 � p2. The function prop.test is used to being called as prop.test(x,n) where x is the number favorable and n is the total. Here it is no different, but since there are two x's it looks slightly different. Here is how
Week 1 Week 2 Favorable 45 56 Unfavorable 35 47
> prop.test(c(45,56),c(45+35,56+47))
2-sample test for equality of proportions with continuity correction
data: c(45, 56) out of c(45 + 35, 56 + 47)
X-squared = 0.0108, df = 1, p-value = 0.9172
alternative hypothesis: two.sided
95 percent confidence interval:
-0.1374478 0.1750692
sample estimates:
prop 1 prop 2
0.5625000 0.5436893
We let R do the work in finding the n, but otherwise
this is straightforward. The conclusion is similar to ones before,
and we observe that the p-value is 0.9172 so we accept the null
hypothesis that p1 = p2.11.2 Two-sample t-tests
The one-sample t-test was based on the statistic| t = |
|
The two-sample t-test is based on the statistic
| t = |
|
. |
We observe that the denominator is much different that the one-sample test and that gives us some things to discuss. Basically, it simplifies if we can further assume the two samples have the same (unknown) standard deviation.
11.3 Equal variances
When the two samples are assumed to have equal variances, then the data can be pooled to find an estimate for the variance. By default, R assumes unequal variances. If the variances are assumed equal, then you need to specify var.equal=TRUE when using t.test.
Example: Recovery time for new drug
Suppose the recovery time for patients taking a new drug is measured (in days). A placebo group is also used to avoid the placebo effect. The data are as follows
Suppose the recovery time for patients taking a new drug is measured (in days). A placebo group is also used to avoid the placebo effect. The data are as follows
with drug: 15 10 13 7 9 8 21 9 14 8
placebo: 15 14 12 8 14 7 16 10 15 12
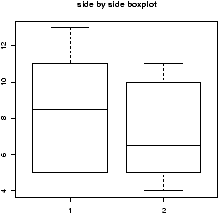
After a side-by-side boxplot (boxplot(x,y), but not
shown), it is determined that the assumptions of equal variances
and normality are valid. A one-sided
test for equivalence of means using the t-test is found. This
tests the null hypothesis of equal variances against the
one-sided alternative that the drug group has a smaller
mean. (�1 - �2 < 0). Here are the results
> x = c(15, 10, 13, 7, 9, 8, 21, 9, 14, 8)
> y = c(15, 14, 12, 8, 14, 7, 16, 10, 15, 12)
> t.test(x,y,alt="less",var.equal=TRUE)
Two Sample t-test
data: x and y
t = -0.5331, df = 18, p-value = 0.3002
alternative hypothesis: true difference in means is less than 0
95 percent confidence interval:
NA 2.027436
sample estimates:
mean of x mean of y
11.4 12.3
We accept the null hypothesis based on this test.11.4 Unequal variances
If the variances are unequal, the denominator in the t-statistic is harder to compute mathematically. But not with R. The only difference is that you don't have to specify var.equal=TRUE (so it is actually easier with R).If we continue the same example we would get the following
> t.test(x,y,alt="less")
Welch Two Sample t-test
data: x and y
t = -0.5331, df = 16.245, p-value = 0.3006
alternative hypothesis: true difference in means is less than 0
95 percent confidence interval:
NA 2.044664
sample estimates:
mean of x mean of y
11.4 12.3
Notice the results are slightly different, but in this example the
conclusions are the same -- accept the null hypothesis. When we
assume equal variances, then the sampling distribution of the test
statistic has a t distribution with fewer degrees of
freedom. Hence less area is in the tails and so the p-values are
smaller (although just in this example).
11.5 Matched samples
Matched or paired t-tests use a different statistical model. Rather than assume the two samples are independent normal samples albeit perhaps with different means and standard deviations, the matched-samples test assumes that the two samples share common traits.The basic model is that Yi = Xi + ei where ei is the randomness. We want to test if the ei are mean 0 against the alternative that they are not mean 0. In order to do so, one subtracts the X's from the Y's and then performs a regular one-sample t-test.
Actually, R does all that work. You only need to specify paired=TRUE when calling the t.test function.
Example: Dilemma of two graders
In order to promote fairness in grading, each application was graded twice by different graders. Based on the grades, can we see if there is a difference between the two graders? The data is
Notice, the data are not independent of each other as grader 1 and grader 2 each grade the same papers. We expect that if grader 1 finds a paper good, that grader 2 will also and vice versa. This is exactly what non-independent means. A t-test without the paired=TRUE yields
In order to promote fairness in grading, each application was graded twice by different graders. Based on the grades, can we see if there is a difference between the two graders? The data is
Grader 1: 3 0 5 2 5 5 5 4 4 5
Grader 2: 2 1 4 1 4 3 3 2 3 5
Clearly there are differences. Are they described by random
fluctuations (mean ei is 0), or is there a bias of one
grader over another? (mean e � 0).
A matched sample test will give us some insight. First we should
check the assumption of normality with normal plots say. (The
data is discrete due to necessary rounding, but the general
shape is seen to be normal.) Then we can apply the t-test as
follows
> x = c(3, 0, 5, 2, 5, 5, 5, 4, 4, 5)
> y = c(2, 1, 4, 1, 4, 3, 3, 2, 3, 5)
> t.test(x,y,paired=TRUE)
Paired t-test
data: x and y
t = 3.3541, df = 9, p-value = 0.008468
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
0.3255550 1.6744450
sample estimates:
mean of the differences
Which would lead us to reject the null hypothesis.Notice, the data are not independent of each other as grader 1 and grader 2 each grade the same papers. We expect that if grader 1 finds a paper good, that grader 2 will also and vice versa. This is exactly what non-independent means. A t-test without the paired=TRUE yields
> t.test(x,y)
Welch Two Sample t-test
data: x and y
t = 1.478, df = 16.999, p-value = 0.1577
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.4274951 2.4274951
sample estimates:
mean of x mean of y
3.8 2.8
which would lead to a different conclusion.11.6 Resistant two-sample tests
Again the resistant two-sample test can be done with the wilcox.test function. It's usage is similar to its usage with a single sample test.
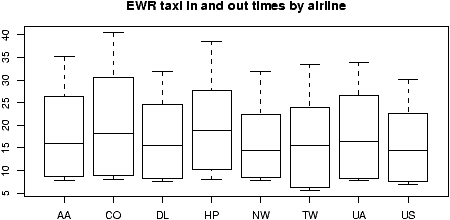
Example: Taxi out times
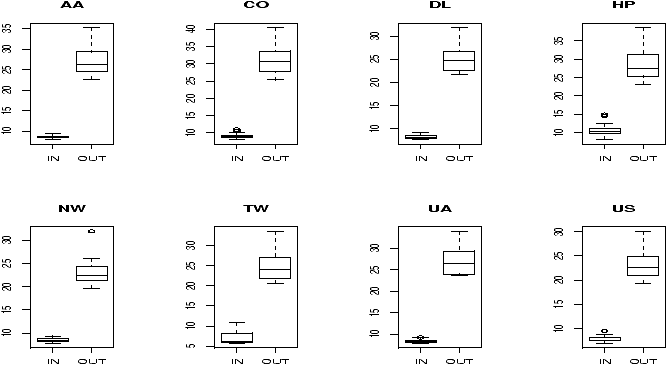
Let's compare taxi out times at Newark airport for American and Northwest Airlines. This data is in the dataset ewr , but we need to work a little to get it. Here's one way using the command subset:
Let's compare taxi out times at Newark airport for American and Northwest Airlines. This data is in the dataset ewr , but we need to work a little to get it. Here's one way using the command subset:
> data(ewr) # read in data set
> attach(ewr) # unattach later
> tmp=subset(ewr, inorout == "out",select=c("AA","NW"))
> x=tmp[['AA']] # alternately AA[inorout=='out']
> y=tmp[['NW']]
> boxplot(x,y) # not shown
A boxplot shows that the distributions are skewed. So a test for the
medians is used.
> wilcox.test(x,y)
Wilcoxon rank sum test with continuity correction
data: x and y
W = 460.5, p-value = 1.736e-05
alternative hypothesis: true mu is not equal to 0
Warning message:
Cannot compute exact p-value with ties in: wilcox.test(x,y)
One gets from wilcox.test strong evidence to
reject the null hypothesis and accept the alternative that the medians
are not equal.
11.7 Problems
- 11.1
- Load the Simple dataset homework. This measures study habits of students from private and public high schools. Make a side-by-side boxplot. Use the appropriate test to test for equality of centers.
- 11.2
- Load the Simple data set corn. Twelve plots of land are divided into two and then one half of each is planted with a new corn seed, the other with the standard. Do a two-sample t-test on the data. Do the assumptions seems to be met. Comment why the matched sample test is more appropriate, and then perform the test. Did the two agree anyways?
- 11.3
- Load the Simple dataset blood. Do a significance test for equivalent centers. Which one did you use and why? What was the p-value?
- 11.4
- Do a test of equality of medians on the Simple cabinets data set. Why might this be more appropriate than a test for equality of the mean or is it?
Copyright © John Verzani, 2001-2. All rights reserved.